
前调 —— Trap or tease?
”你在做一款游戏,游戏需要打怪,击杀怪物会掉落宝物,宝物可能有很多种,也可能不掉宝,几率不一样但是加起来为1,请写一个function,按照几率返回掉落的宝物。”
这是前两天老板面试一个候选Senior Engineer出的算法题,我作为面试旁观者心想:老板你出的这个题,也太简单了吧!!!!这叫Senior?赶紧给我升职加薪!!我分分钟搞定。可是后来被生生的打脸了,他说:一道好的面试题一定是深入浅出的,让面试者不断发掘更优秀的解题办法,这个探索过程才是Engineer的核心能力,而不是上来就是一道不负责任的LeetCode动态规划。那么这个问题到底是有意思在哪里呢?它乍一看非常简单,就是一个抽奖问题,比如我们抽中金奖概率为2%,抽中银奖概率为3%,抽中铜奖为5%,然后抽不中概率为90%,那我们马上就能写一个很简单的版本出来:
Linear Search
//Prize and Probablity (真黑心啊这几率。。。)
var prizeMap = map[string]float64{
"gold": 0.02,
"silver": 0.03,
"bronze": 0.05,
"nothing" : 0.9,
}
func luckyDraw(prizeMap map[string]float64) string{
rand.Seed(time.Now().UnixNano())
random := rand.Float64()
for k, v := range prizeMap {
if random < v {
return k
}
random -= v
}
return "nothing"
}
我: 老板你看!算法很简单,我先把所有的candidate和对应的几率放进一个map,然后通过随机数(伪随机)生成一个小数,然后按照顺序减掉map里面的几率值,最后减不掉的就是对应的选项。
老板: 这个方法的时间和空间复杂度都是多少呢?
我: 空间O(n), 时间O(n), 很快了吧~
老板: 嗯嗯那我要是有10万种奖品种类呢?你这个是不是有点慢啊。
我:啊这。。。
老板:再比如说我先在要加一个钻石奖的选项,概率为1%,其他的不变,你该怎么改数值呢?
我:啊这。。。

老板: 你再想想
我:好的
中调 —— Engineering the way through
I always believe that a good software engineer should be a good product owner with user perspective – Brabalauwka
面试中的算法题我一直非常鄙视,觉得日常生产中根本用不到。现在才发老板出的题目都别出心裁,考算法的过程中其实有很多环节都是很重要的:面试者能否清晰的定义面试官出的题目需求(需求定义与理解),提出一些input和output并且询问理解是否正确(和PM的需求沟通), 快速设计算法并且沟通思路(技术评审),写出算法并且思考edge case(快速开发测试),思考更优解(维护与性能优化)。所以这道题完全满足了这个思路,你不仅仅要考虑每次抽奖的算法,还要考虑日常生产中可能出现的情况。
Binary Search
经过一些思考我得到了以下办法:
//DataSet with weighted collection
var weightedPrizes = map[int][]string{
1: []string{"Dyson", "iPhone"},
2: []string{"XBox", "Switch"},
3: []string{"Speaker", "AirPods"},
50: []string{"nothing"},
}
//User Closure to create the function
func getLuckyDrawFunc(prizeMap map[int][]string) func()string {
//Prepare a linear arrangement of all probabilities
current := 0
//Linear prizes markers
prizeRange := make([]int, 0)
//Actual Prizes
actualPrizes := make([]string, 0)
//Make prize markers
for weight, prizes := range prizeMap {
for _, prize := range prizes {
current += weight
prizeRange = append(prizeRange, current)
actualPrizes = append(actualPrizes, prize)
}
}
rand.Seed(time.Now().UnixNano())
//return the func that used to do lucky draw
return func() string {
random := rand.Intn(current)
//Binary Search the prizeRange
low := 0
high := len(prizeRange) - 1
for high >= low {
mid := (low + high) / 2
if random < prizeRange[mid] {
high = mid - 1
} else {
low = mid + 1
}
}
return actualPrizes[low]
}
}
我:为了满足方便的加减奖品池,更改几率:我们使用用权重计数的map来储存奖品对应的权重,每次更改map新增或者删减奖品我们就重新生成一次里面的奖品几率。这是工程中的优化实现。同时,使用闭包来保护隐私~ 为了减少每次抽奖的时间复杂度,我们建立一个递增的奖品对应的marker,然后通过Binary Search的方法来搜索。
老板:空间和时间复杂度呢? 我:空间复杂度O(3n), 准备时间为O(nlog(n)), 抽奖时间复杂度O(log(n))
老板:不错!一般面试者写成这样我就给过了,但是还有更优解,我面试了这么多人还没有一个人写出来过。
我:。。。。。。我再研究研究。。。
老板: 这个东西叫做Weigthed Random Sampling, 我们后端用到的Load Balancer算法之一。而且能应用到生活中的各个领域
后调 —— Algorithms are sexy
之所以Binary Search不算最优秀的一种接法是因为在二分查找,移动指针的时候很容易出现+1,-1等指针错误或者index out of range error。所以我思考了很久更优秀的解法,也问了朋友能不能提供一些想法,可是我们都没有更好的灵感。最后,朋友发给的我一篇文章令我非常动容,令我感触最深。更优秀的算法出现了:这篇文章介绍了两种极致的加权随机采样算法,它们太优美了;让人不得不惊叹创造者的思想。所以下面的部分我主要用通俗的方法来介绍这两种算法的魅力。
The Hopscotch Selection
我们回顾下linear search算法,核心原理是产生一个从0到1随机数比如0.687,然后挨个减去我们的候选几率直到这个随机数比候选几率小,就找到了对应的选项。首先我们把用float64代表的几率换成int权重,然后相加起来拿到权重和也能进行这样的算法运算;前提是所有的权重加起来能不超过int64的限制。那么HopScotch的精华在于哪里呢,当然在于Hop了~
//interface{} has the format of prize name and weight
type PrizeCollection [][]interface{}
var a = PrizeCollection{
{"Dyson",1},
{"iPhone",1},
{"XBox", 2},
}
func getHopScotchFunc(collection PrizeCollection) func() string {
//Reverse Sort the Weights
sort.Slice(collection, func(i, j int) bool {
return collection[j][1].(int) < collection[i][1].(int)
})
sum := 0
collectionWeightSum := make([]int, len(collection))
for i := 0; i < len(collection); i++ {
sum += collection[i][1].(int)
collectionWeightSum[i] = sum
}
rand.Seed(time.Now().UnixNano())
//return the func that used to do lucky draw
return func() string {
target := rand.Intn(collectionWeightSum[len(collectionWeightSum)-1])
guessIndex := 0
for true {
if collectionWeightSum[guessIndex] > target {
break
}
//Retrieve the actual weight of that index
currentWeight := collection[guessIndex][1].(int)
//Calculate the difference between the current sum and the target
hopDistance := target - collectionWeightSum[guessIndex]
//Calculate the safe distance (indice) to jump
hopIndex := 1 + hopDistance/currentWeight
//Jump
guessIndex += hopIndex
}
return collection[guessIndex][0].(string)
}
}
算法的第一部分首先要求input是一个map或者所有的奖品对应的名字和权重,之所以要一一对应是因为我们要做sorting,把所有的权重逆向排序,然后一次向家所有的权重,依然是不能超过int64的限制。排序的好处是什么呢?如果是linear search,权重大的在前面的话会减少搜索的次数,因为权重大的更有可能被选中。linearsearch的核心在于依次减去权重,是一个O(n)的时间复杂度。所以HopScotch算法在于减去权重的过程中进行跳跃,也就是运用了排序后,后面的数字一定比前面小的原理。比如我随机生成了一个数576,第一个数的权重为100。那么,在我不知道576应该落在哪个区间的情况下我可以使用跳跃:(576-100)/100 = 4 我知道后面所有的权重都比当前权重小,也就是说我在拿到576的情况下,我可以至少向后跳跃4个选项而不用去计算这些权重是什么,从而达到了一种远小于O(n)的时间复杂的。
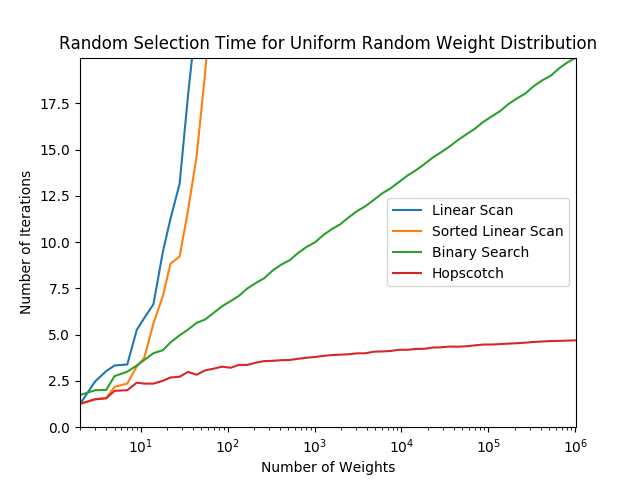
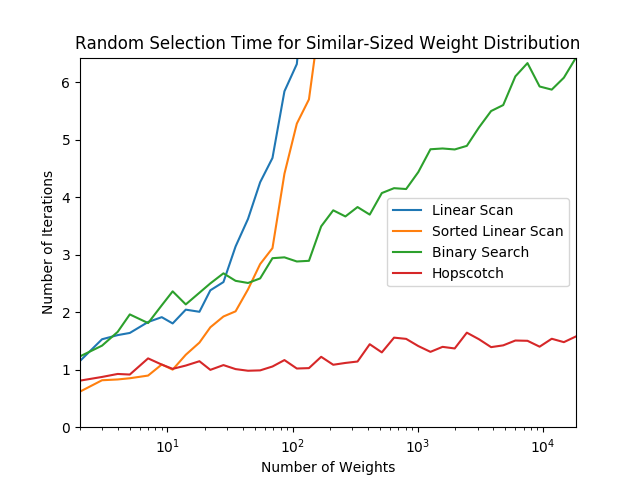
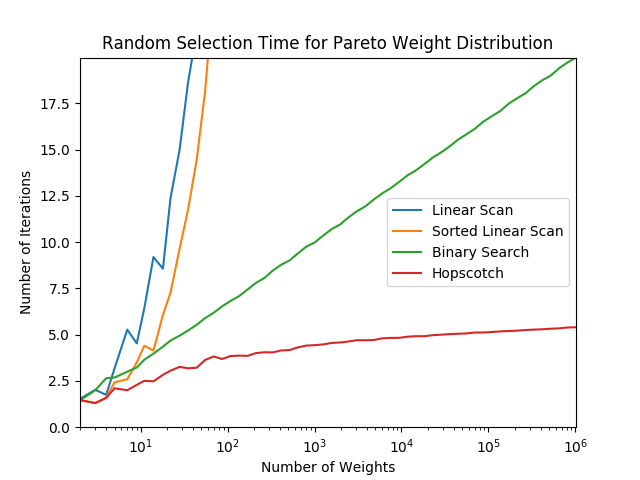
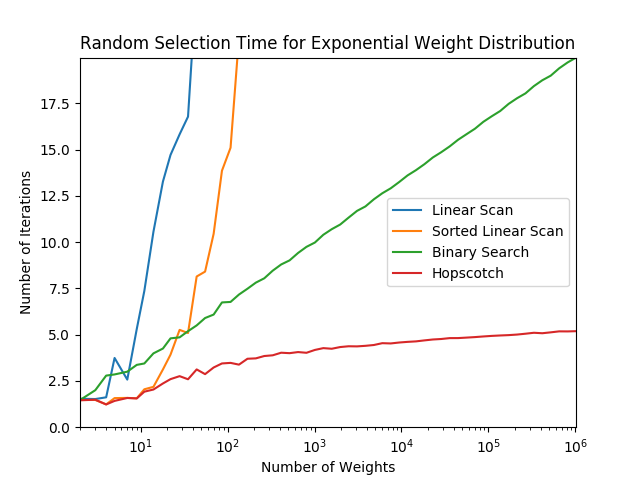
当然这个算法的best case在于所有的权重的一样的情况,那么我们100%只需要O(1)的时间就能选到。worst case在于权重为2的次方依次递减:32,16,8,4,2,1,这就意味着我们每次只能跳跃1个。这个时候时间复杂度接近于linear search。但是!如果是这样的权重分布的话,本身被选中后面的几率就是很小的。作者也对这个算法进行了Benchmark,分别从不同的weight distribution 进行测试,可以看到这个算法表现是非出色:
The Alias Method – Ultimate Form
下面我们就迎来了Alias Method,它是一个极其优美的O(1)复杂度的算法,既然是复杂度为O(1)的算法,他必须在常数时间内找到这个随机数归属的index和这个index所属的candidate。所以我们需要找到一种mapping的算法,这也就是Alias Method的精华所在:
func getAliasFunc(collection PrizeCollection) func()string {
totalPrizeNum := len(collection)
sum := 0
for i := 0; i < len(collection); i++ {
sum += collection[i][1].(int)
}
//Get Average
average := float64(sum) / float64(totalPrizeNum)
//Aliases is a array of [float, int] so we use interface{}
aliases := make([][]interface{}, totalPrizeNum)
//Initialisaition
for i := 0; i < totalPrizeNum; i++ {
aliases[i] = []interface{}{1.0, 0.0}
}
//U can check the explanation first before coming back~
bigWeights := make([][]interface{},0)
smallWeights := make([][]interface{},0)
for index, prizeItem := range collection {
if float64(prizeItem[1].(int)) < average {
smallWeights = append(smallWeights, []interface{}{index, float64(prizeItem[1].(int)) / average })
} else {
bigWeights = append(bigWeights, []interface{}{index, float64(prizeItem[1].(int)) / average })
}
}
bigWeightsPosition := 0
for i := 0; i < len(smallWeights); i++ {
aliases[smallWeights[i][0].(int)] = []interface{}{smallWeights[i][1].(float64), bigWeights[bigWeightsPosition][0].(int)}
bigWeights[bigWeightsPosition][1] = bigWeights[bigWeightsPosition][1].(float64) - (1 - smallWeights[i][1].(float64))
if bigWeights[bigWeightsPosition][1].(float64) <= 1 {
smallWeights = append(smallWeights, bigWeights[bigWeightsPosition])
bigWeightsPosition++
if bigWeightsPosition >= len(bigWeights) {
break
}
}
}
//---------------------------return the func that used to do lucky draw
rand.Seed(time.Now().UnixNano())
return func() string {
target := rand.Float64()*float64(len(collection))
targetAlias := int(target)
targetWeight := target - float64(targetAlias)
if targetWeight < aliases[targetAlias][0].(float64) {
return collection[targetAlias][0].(string)
} else {
return collection[aliases[targetAlias][1].(int)][0].(string)
}
}
}
由于golang缺乏复杂的数据结构和好用的mothod,代码比较不可读,奉上python版本:
def prepare_aliased_randomizer(weights):
N = len(weights)
avg = sum(weights)/N
aliases = [(1, None)]*N
smalls = ((i, w/avg) for i,w in enumerate(weights) if w < avg)
bigs = ((i, w/avg) for i,w in enumerate(weights) if w >= avg)
small, big = next(smalls, None), next(bigs, None)
while big and small:
aliases[small[0]] = (small[1], big[0])
big = (big[0], big[1] - (1-small[1]))
if big[1] < 1:
small = big
big = next(bigs, None)
else:
small = next(smalls, None)
def weighted_random():
r = random()*N
i = int(r)
odds, alias = aliases[i]
return alias if (r-i) > odds else i
return weighted_random
这个算法的核心原理是把候选人按照候选的Average的weight进行分治。假设我们有以下几种候选和对应的weight:
var a = PrizeCollection{
{"Dyson",1}, //20%几率
{"iPhone",1}, //20%几率
{"Nothing",3}, //60%几率
}
//创造n个候选Bucket,n = len(PrizeCollection)
aliases: [{候选Bucket0}, {候选Bucket1}, {候选Bucket2}]
//所以这三种奖品的平均值为
avg := 1+1+3/3 = 5/3
small = [
{"Dyson","候选Bucket0","weight/avg => 3/5"},
{"iPhone","候选Bucket1","weight/avg => 3/5"},
]
big = [
{"Nothing","候选Bucket2","weight/avg => 9/5"}
]
所有比平均值小的会被分到一个组,所有比平均值大的会被分到另一个组,精华来了,我们可以把每个小于Avg的候选人放进他们所在的那个index的Bucket,但是每个Bucket容量为多少呢?容量为Avg,我们用1代表,小于Avg的候选人所占部分在数组中用一个小数代表!那说明我们还有一些富裕地方(Dyson只占一个Bucket的3/5)。那么我们可以为每个小于平均值的的Bucket配平一部分权重大的候选人(把大的拆分进每个小候选人)从而填平的状态
//我们率先用候选bucket2填平候选bucket0所在的Dyson
aliases: [{3/5, "填平部分来自候选Bucket2"}, {候选Bucket1}, {候选Bucket2}]
//then 现在的候选Bucket2对应的 {"Nothing","候选Bucket2","9/5 - 2/5 => 7/5"},他任然大于1
//then 继续配平
aliases: [{3/5, "填平部分来自候选Bucket2"}, {3/5, "填平部分来自候选Bucket2"}, {5/5,没有填平}]
所以我们生成一个从0到bucket数量的float假设为1.85,我们就知道1.85会分配到Bucket1,但是其中的0.85是bucket中的哪部分呢?3/5的部分来自于本Bucket(也就是iphone),2/5的部分来自于Bucket2的填平(也就是Nothing),0.85>3/5所以是来自Bucket2的部分!按照这样,我们就能用随机数的整数部分表示选到了哪个桶,Bucket下标来表示当前Bucket桶所在的Prize是什么,然后用随机数的小数部分来获取我们到底使用这个桶的哪个部分,如果是填平部分我们就选择填平部分的那个Bucket!!再回去看一看这个算法是不是很清楚了呢!
我惊叹于这个算法的核心魅力在于mapping,巧妙的利用了数组下标作为当前Bucket的index,数组只存两个值一个是当前Bucket的阈值,另一个是用于填平当前Bucket的另外一个Bucket的下标。从而实现了O(1)的时间复杂度
后记
如果你看到了这里说明你对知识的好奇超过了我惨淡的文笔。记录算法的学习过程能够帮助一个程序员加深印象。同时也能够锻炼我将思维转化成有结构的文字的能力。希望自己能够保持这份好奇继续了解更多吧~~
A Faster Weighted Random Choice Bruce Hill February 2, 2017
Darts, Dice, and Coins: Sampling from a Discrete Distribution Keith Schwarz December 29, 2011
25 March 2022