
The weekend started as any other, but it quickly took an unusual turn when our users reported a bizarre issue on our App. Right on Monday I found myself bombarded with feedback indicating that the chat page was displaying strange languages.
I work as the backend developer of the Instant Messaging (IM) Team in our company. The banner in the first picture, the action bar in the second picture are under my domain where they are dynamically loaded from the server. In contrast, other part of the app display was fine, so I would say this was extremely rare.
Normally, all app client’s HTTP requests will attach common parameters including app display language (e.g., lang=EN) by the App network framework. Its impossible that the issue came from the client side. I started to check the log and realised a lot of error logs during the weekend. It started on Friday afternoon, and yes, that timing was crucial.
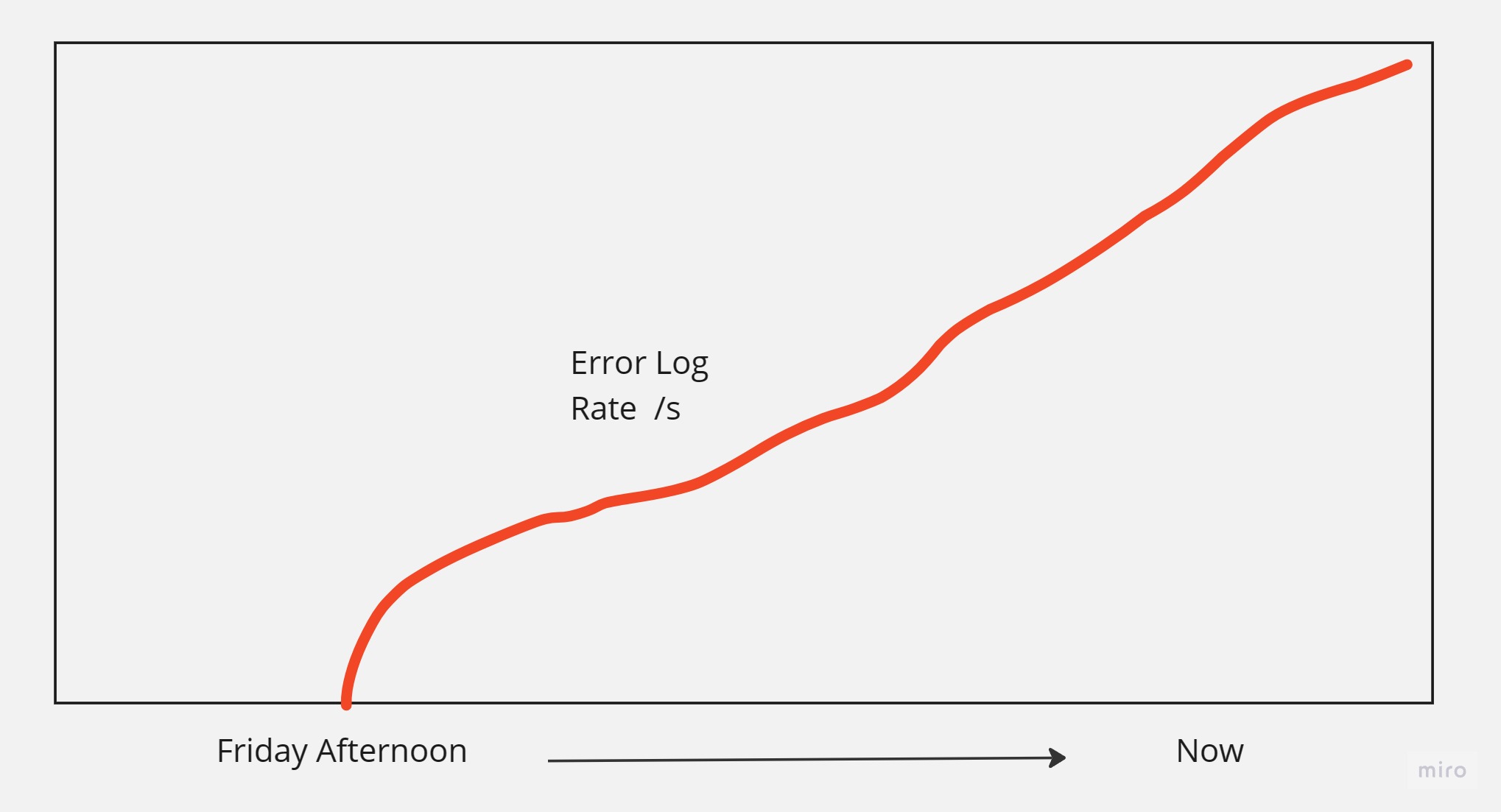
Two things were wired, firstly these error logs were outside of our usual tracing framework, suggesting they were produced elsewhere, possibly by an external sidecar or SDK. Secondly, the rate of error occurrences was increasing, not the total number of logs, indicating that the situation was deteriarating.
Just as I delved into the logs to identify the source of the issue, a colleague from the language translation SDK team reached out to me via Lark,(working IM). He informed me that our service had been bombarding the translation server with too much requests for non-existing languages, and this was causing undue stress on the language server.
I need to pause here and explain to you how translation worked on our App. The banner displayed on the chat page (Fig. 1) was a pre-translated, fixed notice available in 150+ languages. We did not do in time translation. The server just retrieved these fixed strings from the language SDK using a KEY+Language combination.

So these error logs are from the SDK but why these error logs have little context info? My colleague then explained the inner workings of the SDK: to reduce the language server’s load and reduce latency, the SDK would cache query results with the KEY+LANG combination, withing the memory, while updating the cache with a batch request to server every 30 seconds to fetch any new fixes. So the logs are actually deteched with regular framework.
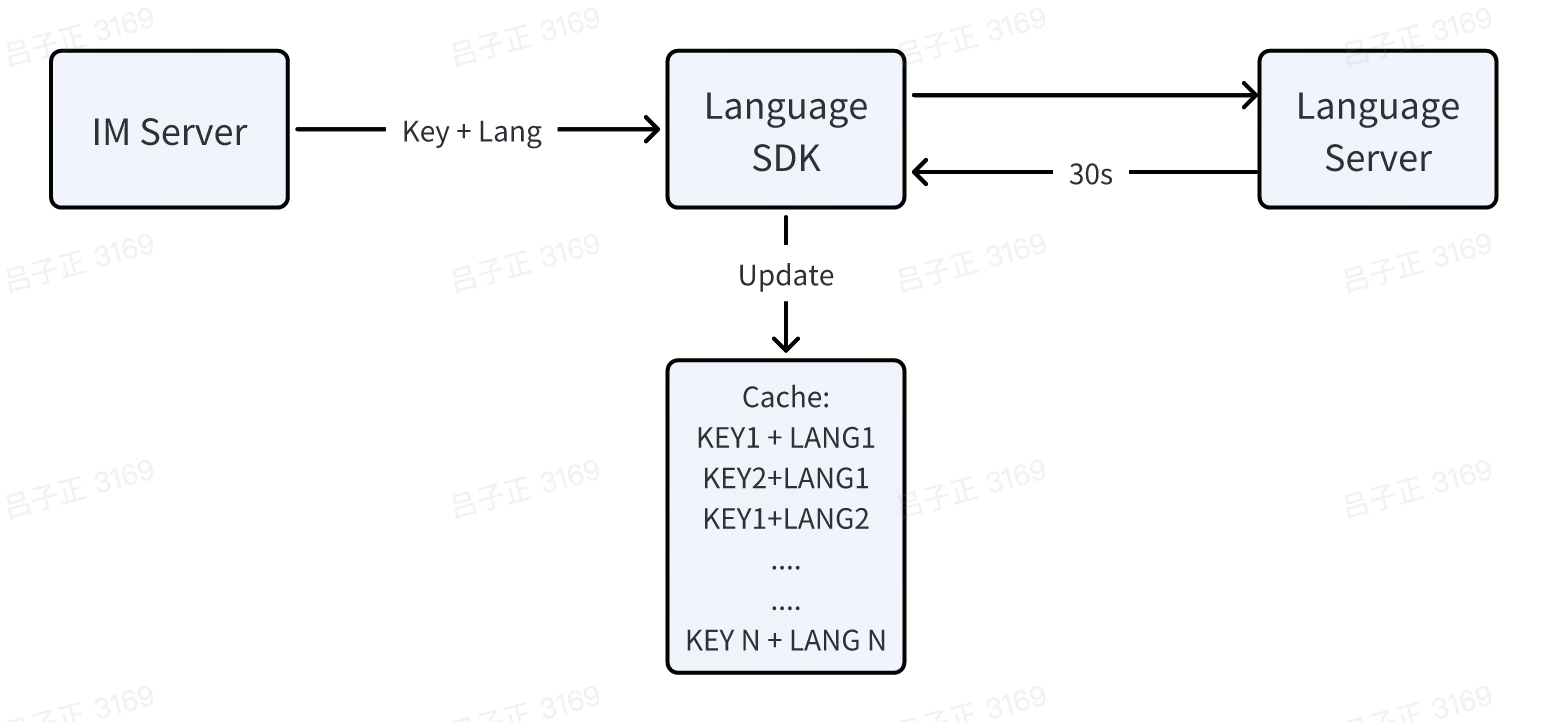
This caching mechanism meant that any request for a non-existing language would continuously trigger updates, eventually overwhelming the server as the number of non-existing languages kept increasing, explains the cause of increasing error log rate.
The root cause was that there are a lot of non-existing languages like below:

Right now I knew what the issue was but what was the cause of continuously incureasing wrong languages? Luckily, I also knew the cuase, because I did a server version release and upgraded that microservice on Friday Afternoon(forgive me). The release involved six stacked commits, one of which must be responsible for the language parameter issue.
So after I rolled back the release, I did a thorough inspection on all code changes among these 6 commits. I was pretty sure all of them were clear and fine! Also, the automation test, on the online environment did not detect the error!! FML, what happened! I then had to choose release the commit changes one by one and test it out on the online env.
Two thousands years later, I finally found out the commit that caused the issue– after browser the code diff for all the go.mod changes. I figured out a change in our biz framework SDK.
// old
func (a *adapter) GetHeader("lang") string {
var lan []byte = c.Param["lan"].
return string(lan)
}
// new
func (a *adapter) GetHeader("lang") string {
var lan []byte = c.Param["lan"].
return *(*string)(unsafe.pointer(&lan))
}
OMG, what have you done bro? How would you ever wanna use this kind of black magic in a company-wise framework to optimise performance!!
The change involved a forced conversion that copied the slice header struct to a new string header struct, sharing the same data pointer. While this avoided data copying and improved performance, it rendered the resulting string vulnerable to modification if the underlying []byte was altered.
// string header
type stringStruct struct {
str unsafe.Pointer
len int
}
// slice header
type slice struct {
array unsafe.Pointer
len int
cap int
}
So here is what happened. Normally, this would not be an issue, as the memory was recycled after each request ended. However, our outer-level framework, Hertz, a high-performance HTTP framework by ByteDance, utilized a ring buffer []byte buffer pool to optimize memory allocation The memory allocated for each request was recycled after the request ends.
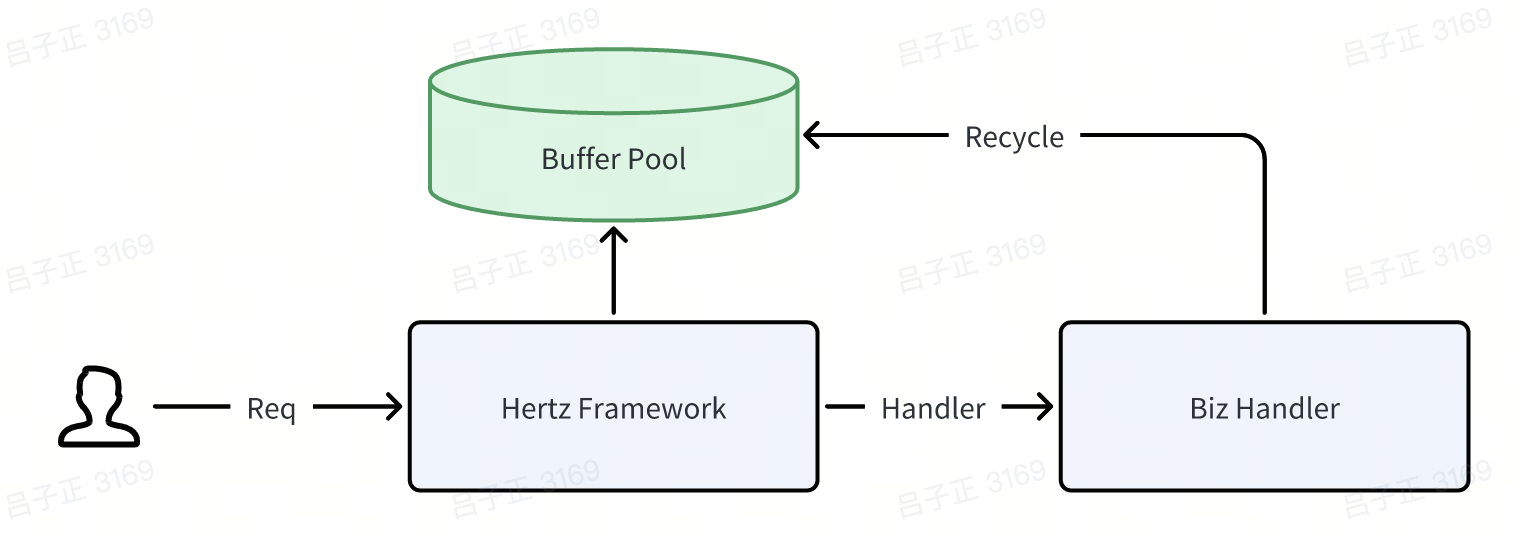
This helped to optimise the performance and reuse the memory. If you are smart enough, you probably find out that during the forced unsafe conversation, the actual data behind the converted string may be modified after the request ends as there is memory use.
Yet, yet, this will not cause any issue as normal, the header string will not be accessed after the request ends. However, we have the SDK’s continuous polling every 30 seconds of all the unsafe cached lang string within the mmomory, leading to a snowball effect of language glitches on our users’ phones. Also the reason why the automation testing framework did not trigger the issue. It only query the testing API once and there was little memory reuse problem on testing env.

So, let this be a cautionary tale of how a seemingly innocent upgrade can unleash language pandemonium. Next time we delve into the realms of “black magic” code, let’s have our wizard hats and potions ready for thorough testing and maybe even a sprinkle of fairy dust for good luck! Also TGIF and no release on Friday
27th July 2023