Introduction
Google, who built GFS in 2006 still faced a lot issue in storing the vast amount of web snapshot data for its search engine. The website content, historical snapshot, meta-data, categories…. And the data size is PB level. Therefore, Google, facing a serious issue in managing its data while the data was increasing at tremendous speed.
- What problem does Bigtable want to solve? Can’t we use a relational database like MySQL to build a cluster to solve it?
- What is the architecture of Bigtable? How does it address the three goals of availability, consistency, and ease of operation?
- What is the underlying data structure of Bigtable? In what way does it achieve high concurrency random reading and writing on HDD?
Scalability: MySQL Cluster
Bigtable’s paper was published in 2006. Before that, if a company faced the problem of “scalability” and the best option was to use a MySQL cluster. Maintaining a MySQL cluster of tens or even hundreds of servers is possible, but is it feasible to have a thousand or even thousands of servers like GFS? What is the common way of scaling out MySQL server?
- Split big tables to smaller tables and split horizontally
- Table sharding and split the table veritcall This is against the idea of scability and the idea of distributed database. However, by then there was no such database this resolved this issue. We need a database that scales when data sets grow and the load balancing would automatically fit into the situation.
Availability: ??
Also, if we have a lot of data, such as hundreds of PB and if the disk is faulty, we want the database is fault tolerant and available and still provide services to public
Solution
Google needs a system that can be highly concurrent, consistent, and support random reading and writing data with scalability.
- Millions of concurrent read-write
- Ease of scale out the database by simply adding servers and disks without affecting availability
- Partition balancing. If there is data being added to a certain partition too much, the system can auto sharding that part of the data
- Parititon tolerance: if certain small node of the db server is not working, the database still work
Compromisation:
- Google gave up the relational model of the BigTable and it does not support SQL
- BigTable does not support cross row transactions (not able to achieve multilevel consistency)
To resolve these issues, Google’s solution is:
- Build the DataBase upon GFS, make BigTable server a stateless computing layer and use GFS to achieve high availability of file. (This was 2006). The computing layer relies on Single Master + Multi Tablet Server, making the entire cluster easy to maintain
- Achieved the first industrial implementation of LSM-Tree like data structure for data storage. (MemTable + SSTable), resolving the high concurrent read and write issue.
- Using Chubby distributed lock service to achieve challenges of consistency issue.
Callback
Introduction to the Google File System (GFS) I did the brief introduction and how GFS works last year (quite a long time ago). Here is a brief callback because Google Bigtable is build based on GFS
GFS
Distributed, high available file system
- Files are distributed in chunks, chunks are hosted in chunk servers
- Different chunks has replica
- Metadata is managed on master and protected from concurrent mutation by lock
- Single master write, use lease to manage primary replica
- Thus, high performance and high avaialbility
- Atomic Record Appends (at least once)
- Need to deal with duplicated data in different replicas (possible)

Atchitecture
- How Bigtable partitioned its data so that it was scaleable
- How Bigtable designed its structure so that there is no single point failure
- How Bigtable supports high throughput and handles millions of requests per second
- General structure of bigtable Some questions to be answered
Data Model
A Bigtable is a sparse, distributed, persistent multidimensional sorted map.
Some features are mentioned here:
- Map –> K, V storage
- Distributed Map –> Map is partitioned, keys are distributed
- Persistent –> Stored and highly available?
- Multidimensional –> ???
- Sparse –> ??
- Sorted Map –> Keys are sorted and therefore the location of the key is binded to certain partition
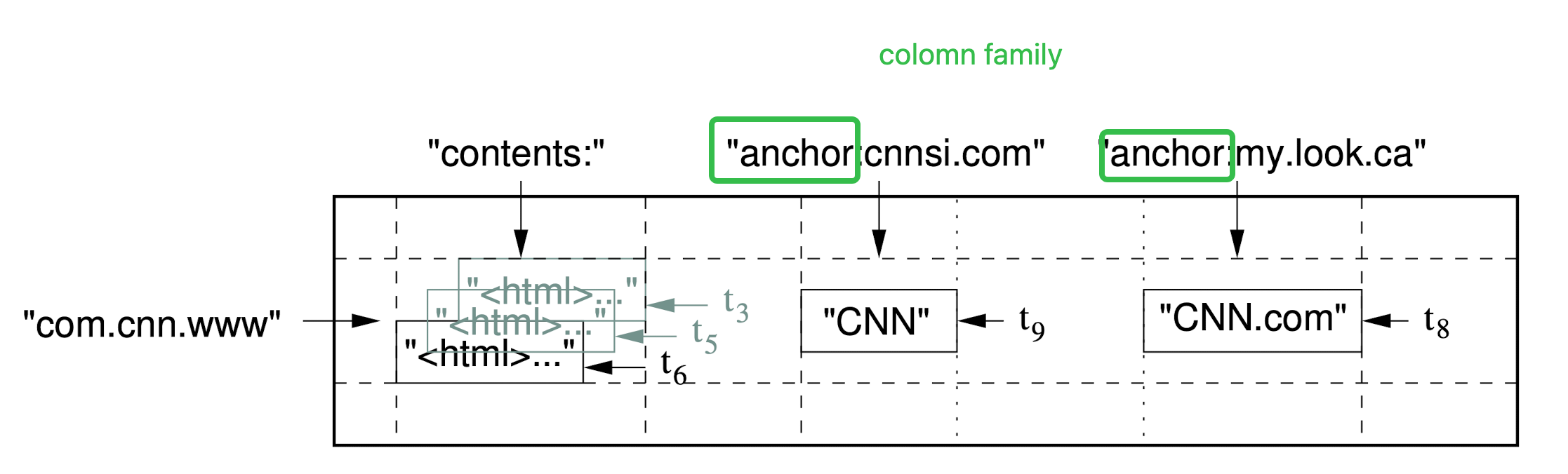
Data Format: Key{RowKey:String, ColumnName: {ColumnFamiy}{Name}:String, Time: int64} –> Val{value}
The data structure is quite simple, and every row of bigtable is just a key value pair where the row key is defined by 3 parts, RowKey, ColumnName and TimeStamp. **In the picture there is another idea called column family **
Column Family

For every column family, the data is stored in same physical location. And for the same rowkey we can keep multiple versions of the value based on the timestamp. The number of historical version can be configured.
The data is structured:
- Column family is configured inside the table meta data and can not be added
- Column name can be added dynamically to column family therefore sparse There is an idea called Locality Group where users can group column familes together and they will be store together in lower level
Row
Any kind of string, limited to 64KB but usually 10 -100 characters. Any operation on data under the same row (read / write) is an atomic action!! (Explain later) This is like the map, the amendment action is
Timestamp
Each ce in a BigTable contains multiple versions of the same data, indexed with timestamps. BitTable timestamps are 64-bit integers, in microseconds. Different versions of a cell are stored in descending order of the timestamps so that the most recent version can be read first.
A good architect pretends that the decision has not been made, and shapes the system such that those decisions can still be deferred or changed for as long as possible. – Robert C. Martin, Clean Architecture
This structure actually provides Google with flexibility to add more columns when the data grows without amending the meta structure of the table
Building Blocks
Tablet
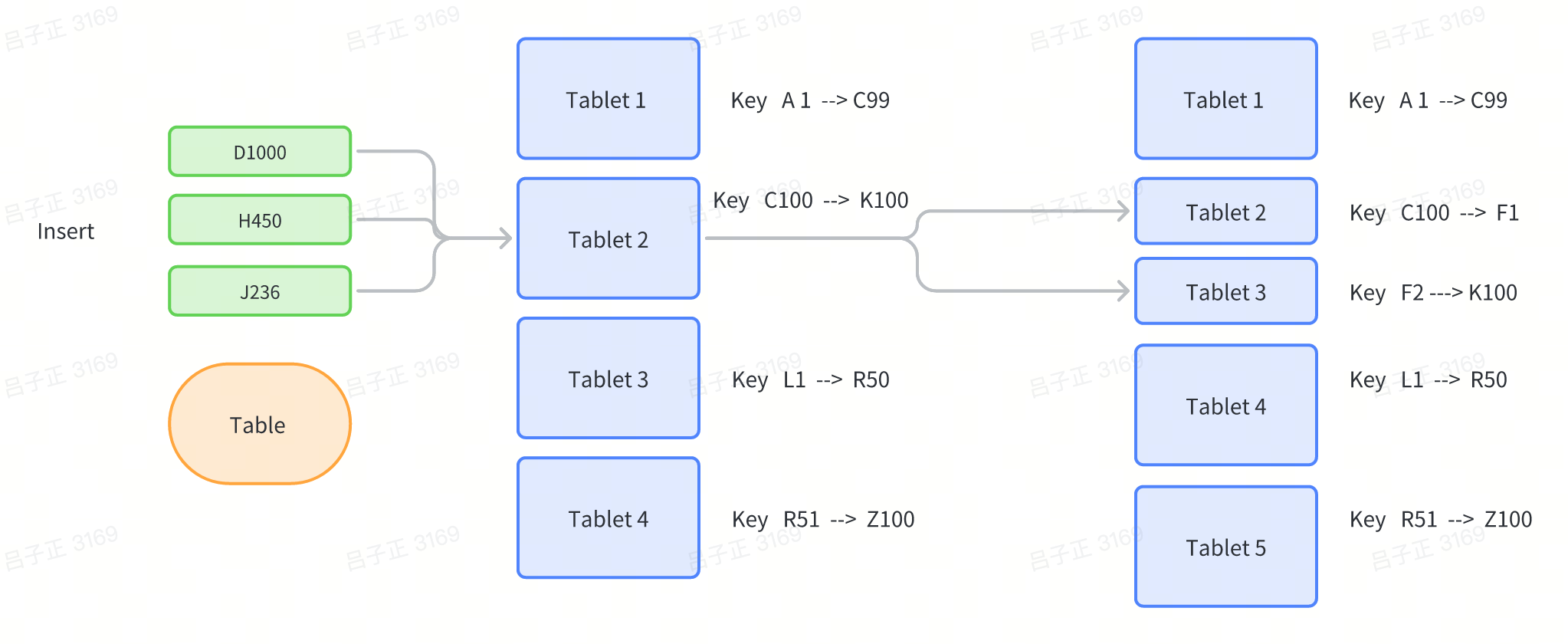
A table consists of a set of rows, and rows have to be partitioned to ensure its a distributed system. So rows are separated into different Tablets. A Tablet is a set of rows and a table consists of a lot of tablets.
- Tablet is like sharding in MySQL
- Tablet is not determined using hashing algorithm but a dynamically allocated range
- Tablet can be split to create more tablets
- mitosis
- This ensures the partition is dynamically expanded and less migration of data is required when a new tablet is added to the table
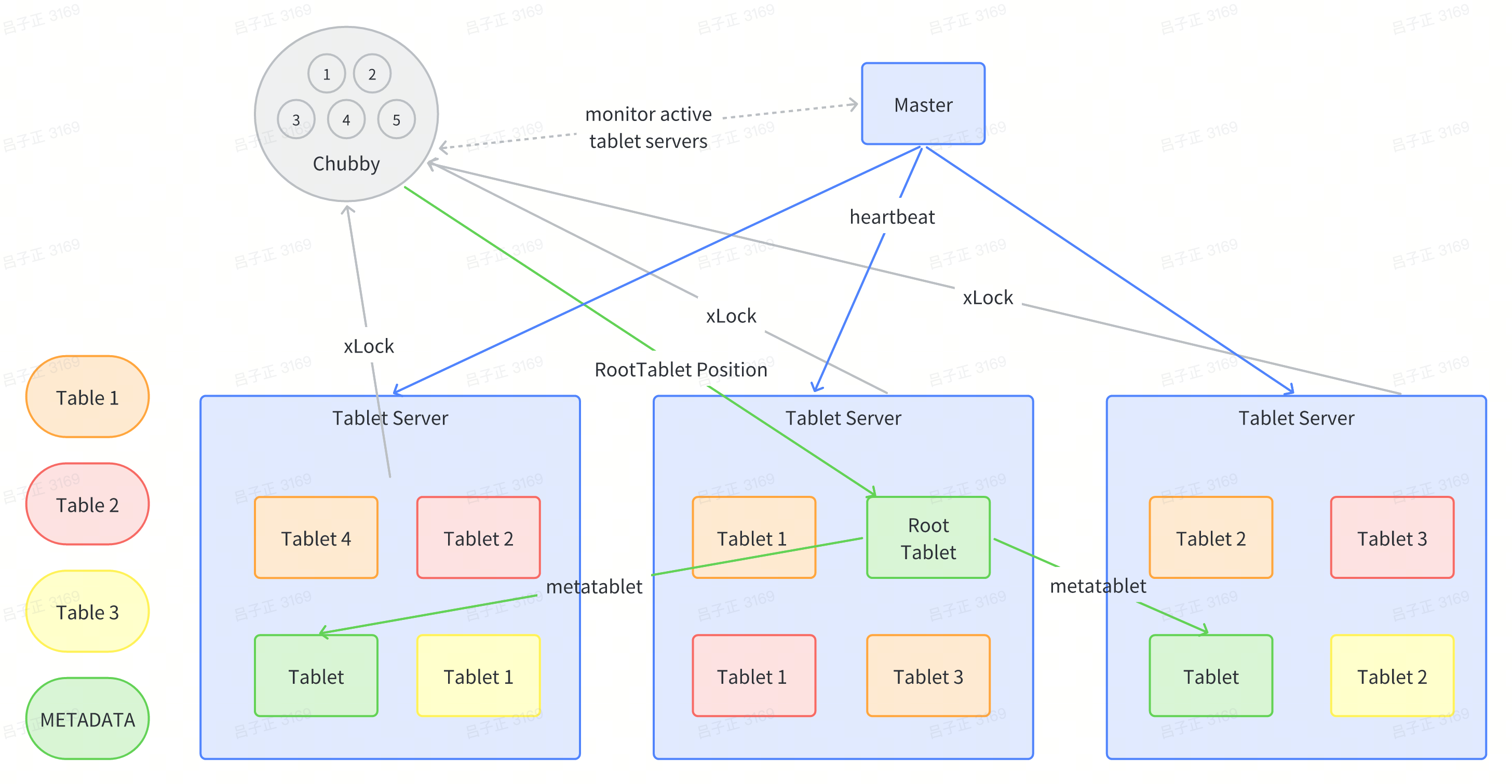
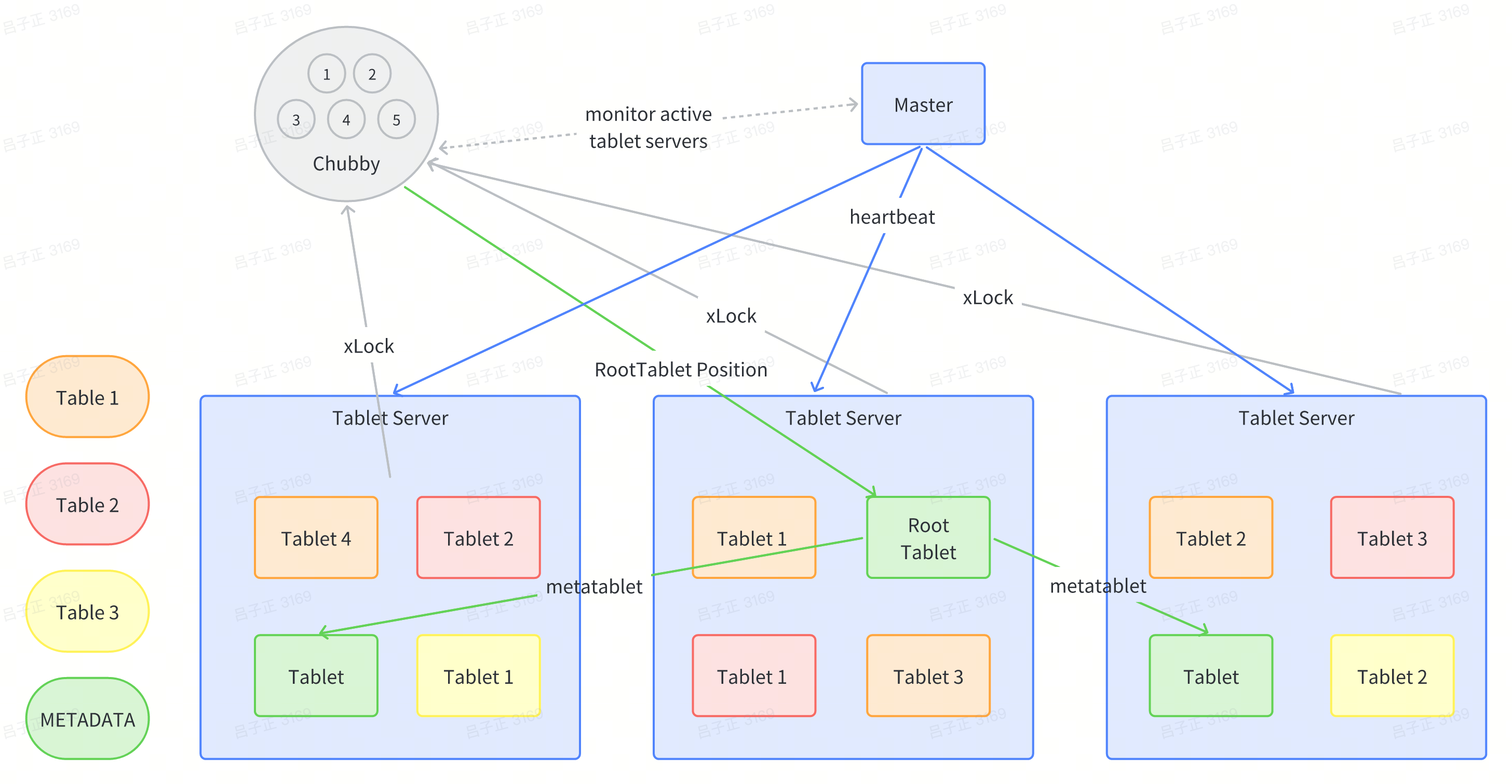
Tablet Manager: Master + Chubby + Tablet Server
Since the partition is dynamically done and we cannot locate the row on which tablet is based on hashing algorithms, we need a manager to manage / store the partition information. We use master + chubby to be the manager ( a distributed lock service, similar to zookeeper)
Tablet Server
With the manager, we know the tablet is just data. We need a database server that provides computation to store/ retrieve data. That is Tablet Server. A tablet server will be allocated with 10-1000 tablets. The tablet server will be in charge of the reading and writing of data on these tablets
This looks tricky as it looks like the tablet is allocated to the local machine of the tablet server! But it its not! The tablet is stored on GFS!! And the tablet server was just allocated different tablets to read from GFS.
Who does this tablet allocation? The master does this thing. Master would rebalance the allocation of the Tablet among the Tablet server based on the CPU usage of Tablet Server.
How is the Tablet store on GFS? Tablet is like a logical idea and the data is stored on GFS in the format of SSTable. SSTable offers a persistent, ordered, immutable K->V mapping. (explained later)
- SSTable is made of a sequence of blocks, 64KB each, configurable
- Block index is stored at the end of every SSTable used to locate the K inside which small block
- When an SSTable is loaded to memory for reading, the Block index is read also to utilise binary search to locate the Key
- Thus, every key reading only requires one disk scan. Also, an SSTable can be read into memory completely to prevent disk scan
Master
So exactly does the master do?
- Master helps allocate tablets to different tablet servers
- Master detects the new creation of tablet server / expiration / migration
- Balancing the load of tablet servers, moving the tablet around
- Garbage collection of the data on GFS
- Manages the table metadata and the change of Table Schema (column family creation / deletion)
Chubby
So it looks like we have this information and what does Chubby do in this system?
Chubby provides a namespace that consists of directories and small files. Each directory or file can be used as a lock, and reads and writes to files are atomic. Each Chubby client main- tains a session with a Chubby service. A client’s session expires if it is unable to renew its session lease within the lease expiration time. When a client’s session expires, it loses any locks and open handles.
- Ensure there is one Master who is active at all timestamp
- Store the bootstrap location of the bigtable data (initialisation process)
- Service discovery of tablet servers adn cleaning their data after job finish
- Store the schema information of Bigtable
- ACL Management
Insights
Why is Chubby necessary?
If there is no Chubby, the basic idea we can think of is to let all tablet server to communicate with the master directly and without Chubby, the most direct cluster management solution I can think of is to have all Tablet Servers communicate directly with the Master, and the partition information (Tablet Infomation) and which Tablet Servers are allocation to which Tablets are also placed directly in the Master’s memory. This approach is the same as we did in GFS.
But this solution makes the master a SPOF(Single Point of Failure) of the master. Of course, we can use Backup Master or Shadow Master to maximize usability. But this comes the first problem, we said in the GFS paper, we can monitor the survival of the master through an external service, and when it hangs, automatically switch to the backup master. But how do we know if the master is really hanging, or it’s just that the network communicating with the master is down?
If it is the latter, we are likely to face a serious issue–there are two masters in the system. At this time, the two clients may think that the two masters are real, and when they write data on both sides, we will encounter the problem of data inconsistency.
So we need a consensus algorithm to ensure there is only one master. Here, Chubby, a cluster of 5 servers, uses Paxos to ensure that there will be no false positives. If chubby becomes unavailable even with 5 nodes, the bigtable becomes unavailable
Why not combine master and chubby as a meta server?
Right side is the design of the abase 2.0 where the metaserver uses raft to achieve consensus. I don’t know why, but I think the answer is yes! But abses 2 was 2021 and bigtable was 2006. Chubby helped the system only have one master and the master is not similar to proxy that synced meta data from the metaserver. The reading and writing logic of the bigtable does not need mastery.
Implementation
Tablet Locations/Management
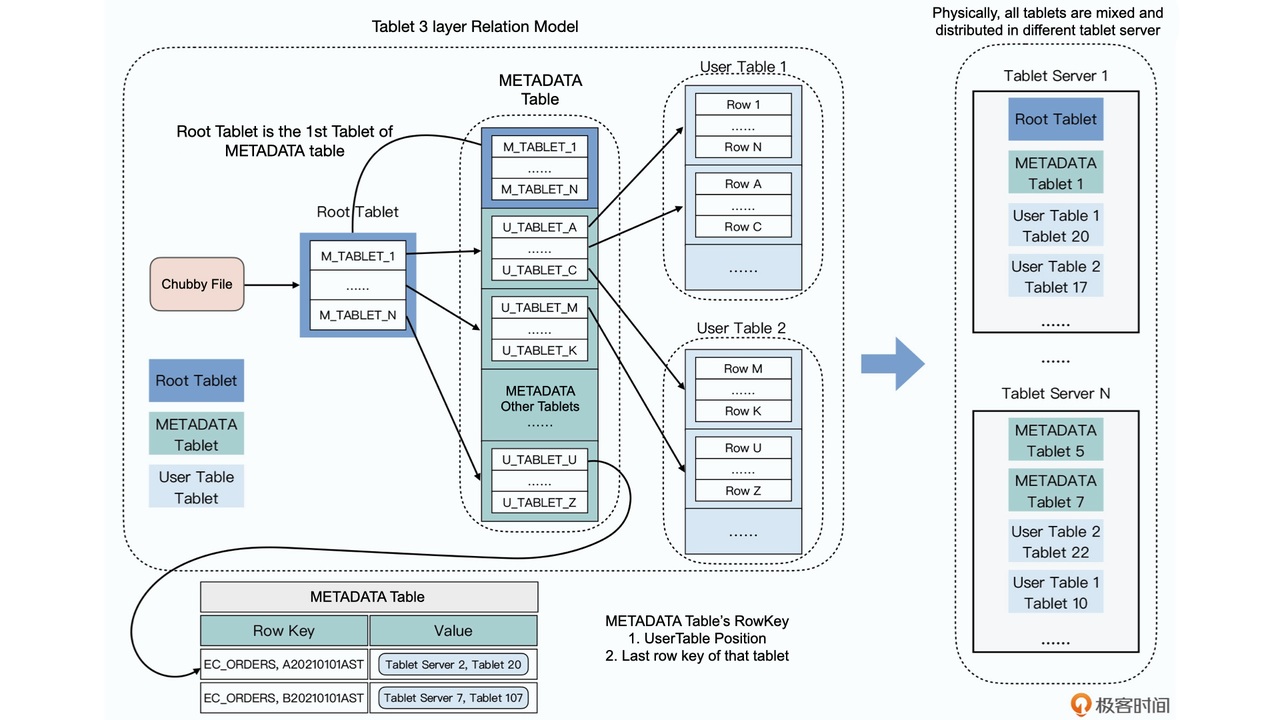
Bigtable uses a very smart method, that is to directly save partition information (tablet) information into a METADATA table (indexing table) of Bigtable.
- The metadata itself is a table of Bigtable and is directly stored in the Bigtable cluster
- Similar to the information_schema table in MySQL, that is, the database defines a special table to store its own metadata.
- MetaData Table itself may have a few tablets and is stored in different tablet server!
- There is a file in chubby for every Bigtable server that points to a special tablet called RootTablet, the file stores the location of the roottablet
- RootTablet is the first partition of the MetaData Table
- RootTablet never splits.
- It stores the location of other tablets in METADATA. The remaining tablet
Diagram
Reading from Bigtable
Here we look at a specific example of reading and writing Bigtable data to help you understand. For example, the client wants to find our order information by order ID, and the orders are stored in the ECOMMERCE_ORDERS table of Bigtable, and the order number to be checked is A20231707RST. So, how exactly does our client query?
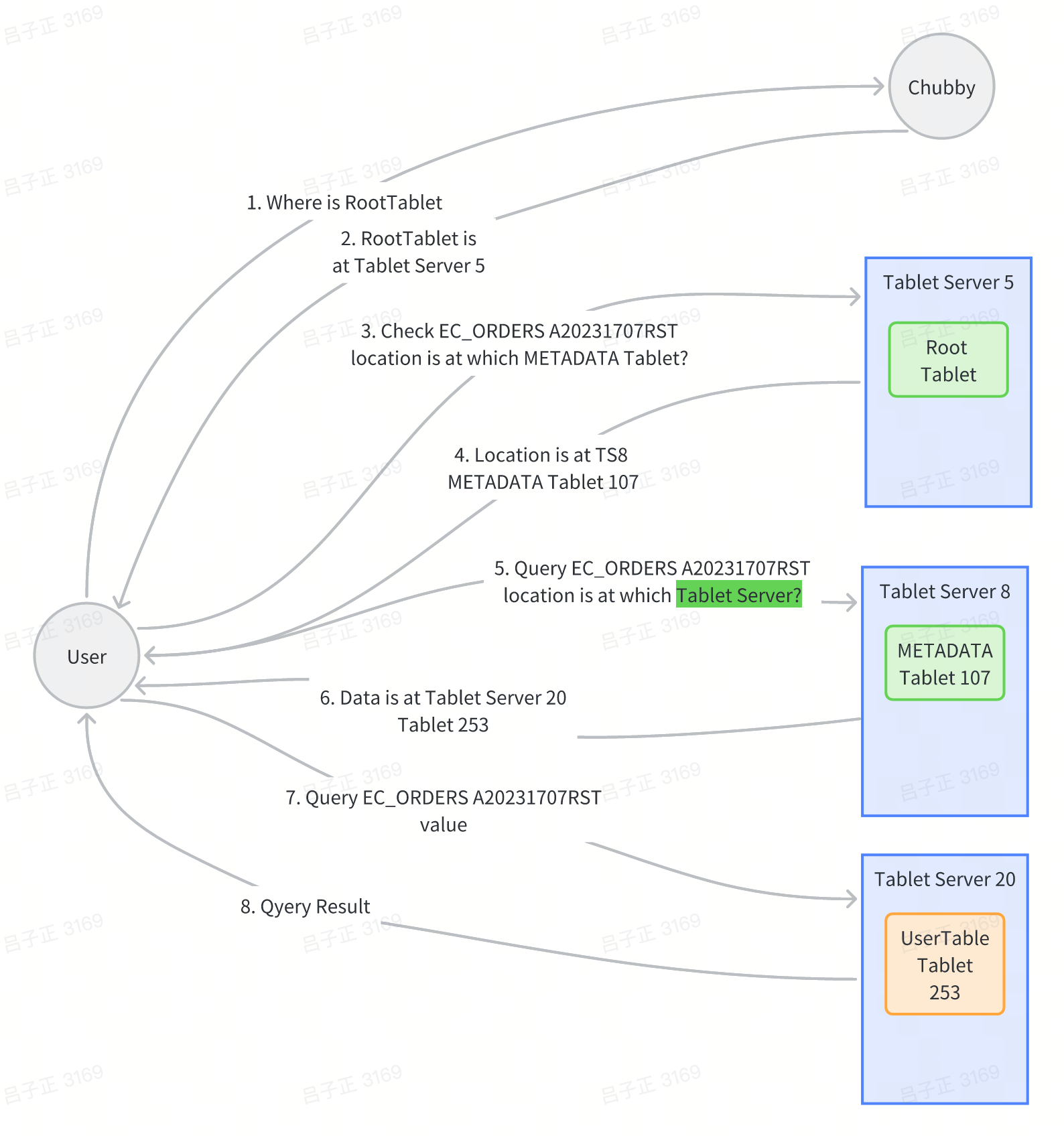
In this process, there are 3rtt (6steps) to find the exact location of the data we wanted to query, and then 4th query gets the actual data. Normally, Bigtable clients will cache the first three query location results to reduce the number of round trips to the network. For the entire METADATA table, we keep them in TS memory, so that the data to be read and written by each request does not need to be read by accessing GFS.
The tablet partition information is a three-layer tablet information storage structure, allowing Bigtable to scale significantly. A METADATA record is about 1KB, and with a limit of 128MB for the METADATA tablet, it can store about 16 billion tablet locations.
The design distributes queries across the Bigtable cluster, preventing concentration on a single master node. The Root Tablet, queried by all, won’t cause much pressure on Chubby or the Tablet server due to its non-split nature and client caching.
Clients don’t need to go through the master for data read/write, ensuring normal operation even if the master node is down. (This design enhances Bigtable’s high availability.)
The process is similar to an operating system startup: —> reading from a fixed location (the first sector of the hard disk in an OS, and the fixed file) —> (where Chubby stores the Root Tablet location in Bigtable) to obtain dynamic information.
Initialisation
Indeed, during the simple process of data reading and writing, the Master is not needed. The Master is only responsible for scheduling tablets and this function depends on Chubby. Here’s how the process works:
- Upon going online, each Tablet Server registers itself to the cluster by obtaining an exclusive lock in a specified directory under Chubby.
- The scan of the METADATA table can only occur after its tablets are assigned. To ensure this, before the scan, the master adds the root tablet to the unassigned set if not assigned earlier. This allows the master to know about all METADATA tablets after scanning the root tablet.
- The Master continuously monitors this directory for new registrations. When a Tablet Server registers, the Master becomes aware of a new Tablet Server available for tablet allocation.
- Tablet allocation can occur for various reasons such as if a Tablet Server fails or is overloaded. In these cases, the Master steps in to reassign Tablets. The exact allocation strategy can be implemented according to individual needs. Not mentioned in paper
- A Tablet Server serves its allocated Tablets based on whether it still exclusively holds the lock on Chubby and if the lock file still exists. If the network connection to Chubby is interrupted, the Tablet Server loses the lock and stops serving its allocated Tablets.
- If a Tablet Server is removed from the cluster, it actively releases the lock and stops serving its Tablets. These Tablets then need to be reassigned.
- The Master checks the functionality of the Tablet Server using a heartbeat mechanism. If a Tablet Server loses the lock or is unreachable, the Master tests by attempting to obtain the lock. If the Master successfully gets the lock, it means the Chubby is alive and functioning and thus implies a problem at the Tablet Server’s end. The Master then deletes the lock, ensuring the Tablet Server no longer serves the Tablets, and the Tablets return to an unallocated state.
- If the network connection between the Master and Chubby experiences issues or their session expires, the Master self-destructs to avoid a situation with two unaware Masters. This doesn’t impact the existing Tablets allocation relationship or the data read/write process of the entire Bigtable.
Tablet Serving
Tablet data is written into GFS. The form of the tablet in GFS comprises several SSTable file. This diagram looks similar as its the core foundation for the well known LevelDB its the first industrial implemented LSM-Tree storage engine. The SSTable is a persistent, ordered, immutable key-value mapping. It is made up of a sequence of blocks, each 64KB in size. The block index is stored at the end of each SSTable, allowing for the location of a key within a small block. When an SSTable is loaded into memory for reading, the block index is read to enable binary search for the key. This means that every key read only requires one disk scan. SSTables can be read into memory entirely to prevent disk scans.

Reading && Writing
// Write
// Open the table
Table *T = OpenOrDie("/Bigtable/web/webtable");
// Write a new anchor and delete and old anchor
RowMutation r1(T, "com.cnn.www");
r1.Set("anchor:www.c-span.org", "CNN")
r1.Delete("anchor:www.abc.com");
Operation op;
Apply(&op, &r1);
// Read
Scanner scanner(T);
ScanStream *stream;
stream = scanner.FetchColumnFamily("anchor"); // column family
stream->SetReturnAllVersions();
scanner.Lookup("com.cnn.www"); // key
for (; !stream->Done(); stream->Next()) {
printf("%s %s %lld %s\n",
scanner.RowName(),
stream->ColumnName(),
stream->MicroTimestamp(),
stream->Value());
}
This code segment is simple and it is just to amend two columns inside the row “com.cnn.www” and interestingly, Bigtable supports single row level transactions, so these two amendments, either both of them succeeded or neither of them did. In GFS callback we mentioned that GFS has no consistency assurance on random record mutation but only guarantees atomic record appendings. Which suits the idea of LSM-T well, that records are append sequentially to the memetable before written to the GFS.

After this diagram you could see that the tablet server is a stateless database engine for the memtable and immutable memtable How to provide high-performance random data reading?
Random writes have been converted to sequential writes, but we still can’t avoid random reads. And following the previous process, you will find that the cost of random reading is not small.
- A random query of data may require multiple accesses to the hard disk on GFS and read multiple SSTables.
- The data structure of MemTable is usually implemented through an AVL red-black tree or a skip list. In the actual LevelDB source code, MemTable chooses to use a skip list as its data structure.
- The reason for using this data structure is simple, mainly because MemTable only has three operations: the first is random data insertion based on row keys, which is needed for data writing; the second is random data reading based on row keys, which is needed for data reading; the last is ordered travel based on row keys, which is used when we convert MemTable to SSTable.
- Both the AVL red-black tree and the skip list perform well in these three operations, with the time complexity of random insertion and reading being O(logN), and the time complexity of ordered traversal being O(N).
The file format of SSTable is actually very simple, essentially consisting of two parts: the first part is the actual row keys, columns, values, and timestamps to be stored. These data will be sorted by row keys into fixed-size blocks for storage. This part of the data is generally referred to as data blocks in SSTable. The second part is a series of metadata and index information, including bloom filters used to quickly filter row keys that do not exist in the current SSTable, and some statistical indicators of the entire data block, which we call metadata blocks. There are also indexes for data blocks and metadata blocks, and these index contents are the meta index blocks and data index blocks respectively.
Optimisation
Bigtable optimizes data access through a combination of compression, caching, and bloom filters.
- Compression: Each block of data is compressed to conserve storage and cache space. This process uses CPU resources to reduce the space required for storage.
- Bloom Filters: Bigtable uses Bloom filters, to quickly identify if an element is part of a set. Each SSTable’s Bloom filter is cached in the Tablet Server, allowing for rapid checks to see if a row key is present in an SSTable file.
- Two-Level Caching: Bigtable provides a two-tier caching system. The high-level cache, or Scan Cache, stores query results. The lower-level cache, or Block Cache, stores entire data blocks obtained from queries. This system reduces the need for repeated hard disk access on the GFS when the same or related data is queried.

Single Row Transaction
Bigtable supports single-row transactions, including single-row read-update-write and single-row multi-column transactions. Although Bigtable is a distributed storage, its single-row transactions are not essentially distributed transactions. This is because the data of a single row in Bigtable is definitely in the same tablet, so it will not span across tablet servers, naturally making it a single-machine transaction. Let’s analyze Bigtable’s single-row transactions from the ACID perspective:
- A: Atomicity is reflected in two aspects: the data in the read-update-write process cannot be changed by other transactions, and the changes of multiple columns either all succeed or all fail.
- C: Consistency doesn’t exist in Bigtable as there are no consistency constraints.
- I: Isolation Level in Bigtable transactions is row-level, and the isolation level is Read Committed (RC), with no other scenarios.
- D: Durability is ensured as Bigtable is based on the GFS distributed file system, and data written successfully is considered reliable. Therefore, for this single-row transaction, the key is to ensure atomicity. For the atomicity of single-row multi-column operations, Bigtable writes to the operation log before writing to memory. If an exception occurs during the write process, replaying the operation log can ensure atomicity. For the atomicity of read-update-write, it can be guaranteed by the Compare and Swap (CAS) mechanism. So, Bigtable’s single-row transactions are very simple, even simpler than MySQL’s single-machine transactions, which may be why the original text did not explain single-row transactions.
Reference