
Motivation (抛砖引玉)
Distributed database / file system is crucial for understanding how our distributed system works. During the progression of all DB/ File systems. Google File System lays the foundation for a massive scalable system. So I would love to share this classic design and if you are interested, can go on with sharing on Bigtable / HDFS / HBASE and other more state of the art solutions.
File System and Distributed File System
- Supports (Create / Open / Read / Write / Close / Delete) I/O
- A Local File System appears on a single machine and has I/O limitation
- A Distributed File System (DFS) as the name suggests, is a file system that is distributed on multiple file servers or multiple locations.
- GFS is released in 2003 and supports more functions than a Local File System, e.g. 1000 storage nodes, over 300 TB of diskstorage,
- MapReduce/BigTable are all based on GFS
Background
By then, SSD is not popular and HDD is still the main medium of data storage and we all know HDD, due to its mechanical structure, it has better performance in sequential read and writes but weak performance on random reads and writes.
Assumptions by Google:
- Component failures are the norm rather than the exception (The file system consists of hundreds or even thousands of storage machines built from inexpensive commodity parts)
- The system stores a large number of large files. (more than 1,000,000 files with more than 100MB)
- The workloads primarily consist of two kinds of reads: large streaming reads and small random reads.
- The workloads also have many large, sequential writes that append data to files
- The system must efficiently implement well-defined semantics for multiple clients that concurrently append to the same file.
- High sustained bandwidth is more important than low latency
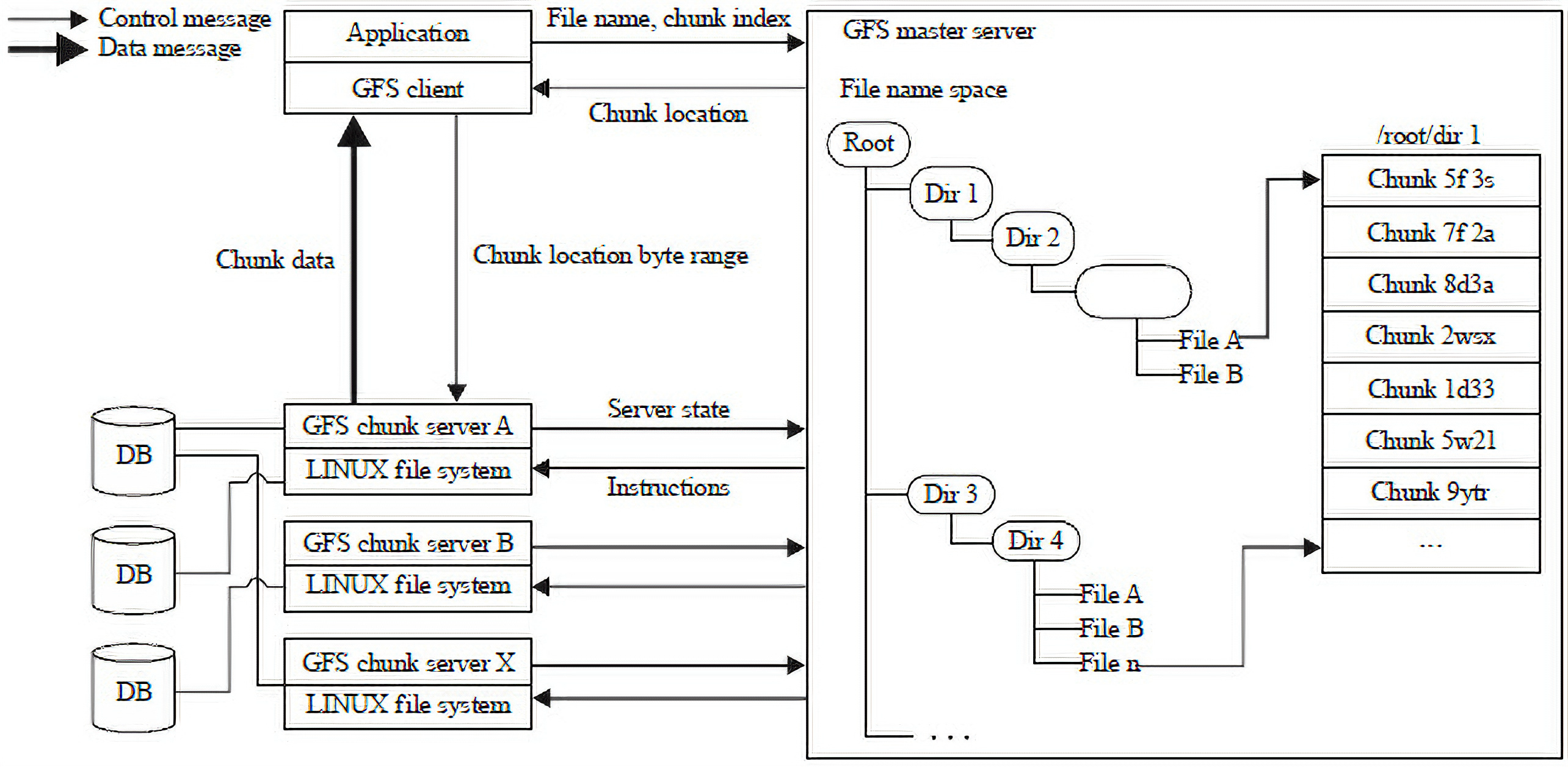
GFS Overall Architecture
A GFS cluster has three types of applications . Every type of application is a special user level process running on standard Linux machine. Client and ChunkServer can be running on the same machine.
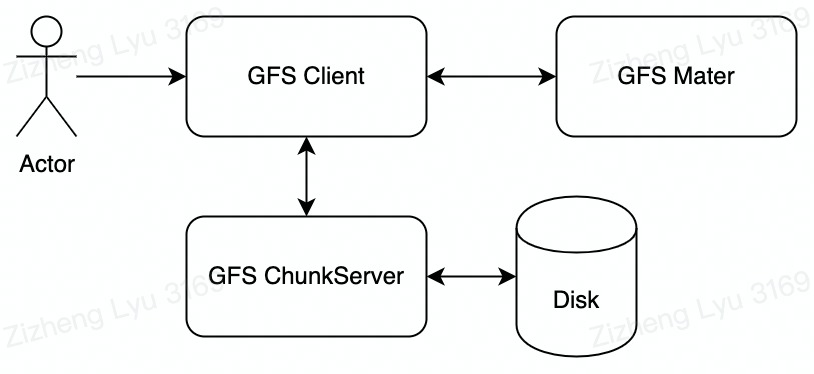
- GFS Master Stores metadata of all chunkservers, manages data position and lease
- GFS ChunkServer Store actual data to the local Linux Machine
- GFS Client. Provide file-system API for applications. Interact with applications
GFS Storage Design
Chunk & Chunk Server
- Considering that a file is big, files are divided into fixed-size chunks. Each chunk is identified by an immutable and globally unique 64 bit chunk handle.
- Each chunk is 64MB in size and, why? This number is a relatively large number for a file.
- A system that uses GFS has to meet the assumption that the file requires storage is large (100MBs+++). It reduces the need for interaction between the system components, such as finding chunk locations and other logics (introduce later)
- A big chunk means the client is more likely to perform many operations on a given chunk, and client can reuse TCP connection.
- Larger chunk size –> Amount of chunk is smaller –> Save MetaData storage and its curcial for GFS
- However, A small file consists of a small number of chunks, perhaps just one. –> Hot chunk issue —> Consistency Issue
- Every chunk will have three replicas (By default). Must store at different chunk server. Google will have a balanced algorithm to choose the chunk server wisely to place new chunks (e.g. A recently created chunk’s chunkserver may not be chosen or the chunk server with more free space will be chosen)

GFS Master Design
MetaData Management
- For a file, the data itself is stored in the format of CHUNK in different CHUNKSERVER so we need a lot of metadata to match the file with the chunks and the properties of all the files we have
- How do we manage this metadata: we definitely need a meta-data server which in this case is MASTER node of the GFS.
- In a distributed system, do we do a single master or a multi master design (TT IM is multi master design)
| Single Master | MultiMaster | |
|---|---|---|
| Pros | Easy, Consistent | Extensible, More bandwidth |
| Cons | Performance Bottleneck | Difficult, Consistency Issue |
| OKR | Reduce MetaData Size, Optimise performance and latency | Designa a distributed meta-data management system and prove its reliability |
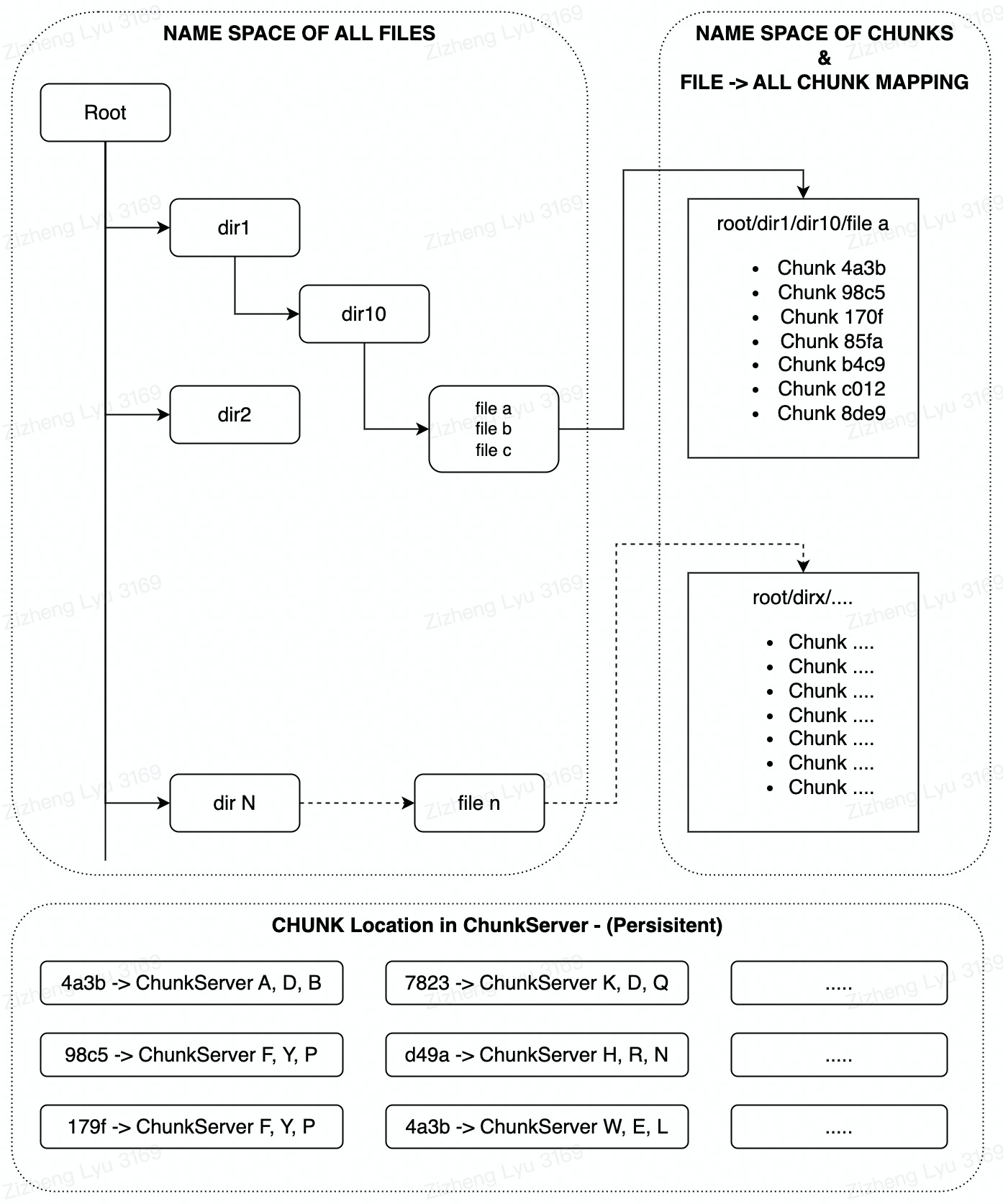
- GFS chose Single Master Design, to store all the meta-data we have for this file system
- The Server stores the namespace tree of the directory (but not stored in a tree data structure the figure is purely for demonstration。(Persistency On)
Google Uses LookUp Table to store the file full name path -> chunk mapping and uses prefix compression to reduce the namespace lookup table size
- The server also store the mapping of the name spaces to the Chunk Locations (Persistency On)
- The Server also stores the chunk position in every chunk server (Not persistent)
- The rough sequence will be : FILE_NAME -> Get all CHUNK_NAMEs of the file -> Get all locations of all the chunks -> READ from the respective CHUNK_SERVER to retrive the data
- The actual reading logic is optimised and wil be mentioned later
Why is the chunk position not stored persistently in the local storage of the master node?
- The chunk server has the final saying on whether a chunk is still on its host
- Chunk server chunks may corrupt frequently
- When the master node starts, it is able to collect information from the chunkserver for the position of all the chunks it has
Performance
Since we are using single master design? Will there be performance issues? A:The master node is optimised in a few ways, so that a single node can provide the entire system with meta data service and all metadata is stored in RAM -> High efficiency
| Design Highlight | Benefits |
|---|---|
| DataMessages are Split from ControlMessages Only control messages will pass through Master DataMessages will be passed directly to chunkserver | Reduce Network Throughput of master significantly |
| GFS Client will cache the metadeta from Master | Further reduce throughput and time of IO interaction between Clinet and GFS Master |
| Increase Chunk Size to reduce number of Chunks as well as meta-data compression | Reduce Memory Consumption of the master node |
- The meta-data will be smaller than 64Byte for a 64MB chunk
- If all data is stored *3 and all metadata is standalone: Then 1TB of data:
- $$\frac{1TB*3}{64MB}*64B\approx3MB$$
- Which means 1PB of file will require less than 4GB of memory of a master
- Which means a GFS cluster is capable of handling that data
GFS Read and Write Process
Reading and writing API is the most important API for the System
- Read Need to be Fast and Accurate (We can sacrifice the consistency by not being able to read the latest version but cannot read wrong values)
- Write need to support: -> Append only and Record Mutation (Overwrite)
- Record Mutation (Overwrite) has to be correct and consistent, –> Secrifice some performance (If performance sensitive can use appending write)
- Appending Operation has to be fast –> There can be errors but we cannot lose the data
GFS used two state-of-the-art techniques in the writing process of the file to the chunkservers, in 2003:
- Flow of Control and Flow of Data Sepration (控制流和数据流分离)
- Data Pipelining (流水线)
Lease (租约)
When a mutation occurs, we are talking about an operation that changes the contents or metadata of a chunk (write / append) operation.
- occurs on all replicas.
- Need to maintain the consistency of all the replicas – GFS has a lease mechanism
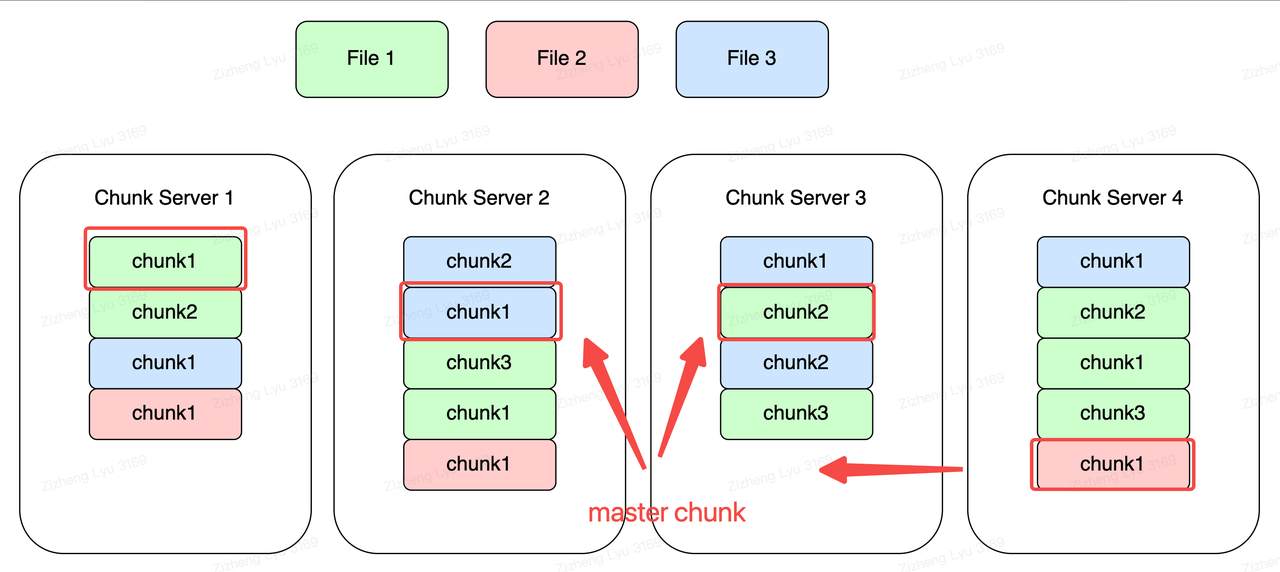
The Master node establishes a lease for a copy of the Chunk, which we call the Primary Chunk.
- The serial order of change that corresponds to that chunk replica is controlled by the primary chunk.
- Lease helps relieve master management load.
- Lease lasts for 60s but can be extended if chunk server wants to extend (Heartbeat from chunk-server <-> master)
- The master may sometimes try to revoke a lease before it expires (e.g., when the master wants to disable mutations on a file that is being renamed)
- Even if the master node loses contact with the primary chunk, it can still safely sign a new lease with another copy of the chunk after the old lease expires.
GFS Write
Record Mutation (Overwrite) Mutation Order
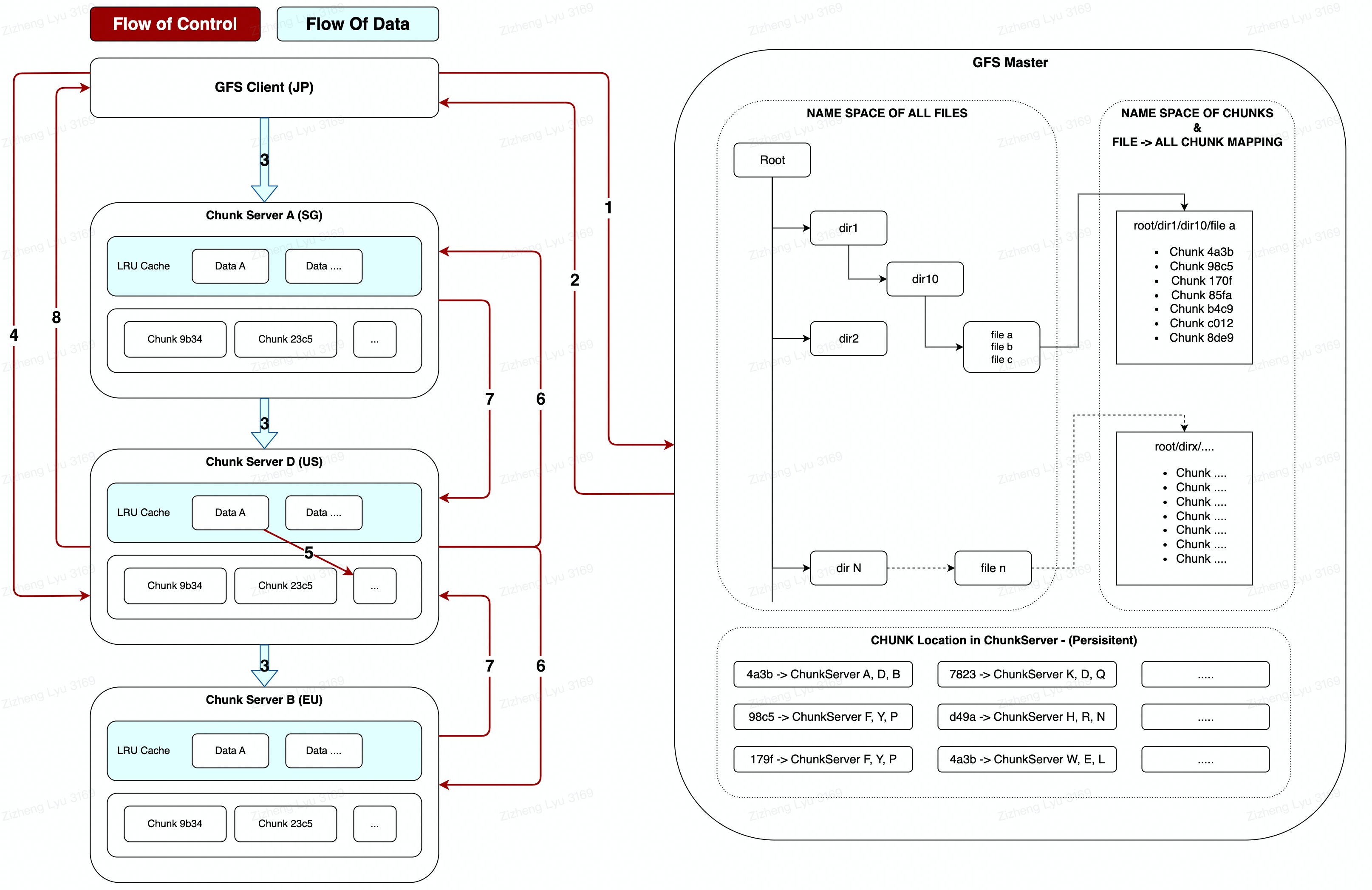
-
Client -> Master: I would love to amend FileA Chunk4a3b
-
Master -> Client: Chunks are located at ChunkServerA,B,D, where ChunkServerD is the primary chunk. (If there is no chunkserver holding the lease, the master will allocate a lease to one of the chunk server (D)
Master node will tell all the replica locations to the client and this will be cached by the client until the primary chunk is no longer available (not reachable / no longer have lease)
-
The client pushes the data to all the replicas. Each chunkserver will store the data in an internal LRU buffer cache
Data pipelining JP(Client) -> SG -> US(Primary) -> EU is much better than JP(Client) -> US(primary) -> SG & US -> EU
Master -> Salve relication is not as good because it involves longer distance data sync (optimised based on networking topology) -
Once the client has pushed all the data to the chunkservers (still in LRU, acked by all chunkservers), the client will then initiate the writing process (metadata amendments) to the primary chunk.
Here we can see that the flow of data and the flow of control is separated where the data to be written is pushed to all the chunk servers alr before the writing process begin The separation of two flows ensures the data consistency is not affected by the data sync process!
-
This writing marks the Data Block that exists in the caches in the primary chunk. The primary –> assigns consecutive serial numbers to all the mutations it receives –> Apply local changes in serial order to the chunks
-
The primary chunk then forwards these serial numbers to all replicas –> replicas will follow these serial numbers to apply changes in serial.
-
Replicas Ack -> Primay
-
Primay Ack -> client
What if error occurs during writing:
Lets say writing is successful in ChunkServeA,B, but failed at ReplicaD. The modified region of the file is left in an inconsistent state. Clients will handle this error by retrying from 3 -> 7 but not from the beginning (What if failed at master? Later will explain consistency model)
How to ensure consistency on different chunks if an record mutation of a file involves 3 chunks? Lets say some chunk fails
Record Append Operation
The record mutation operation can be carried out many times as long as they are serialised because it will not end up with inconsistent results among the chunk replicas .However:
-
What if there is one record mutation that wants to change 3 chunks? And one chunk mutation fails?
-
What if there are multiple clients who want to amend that chunk?
Record Mutation is not recommended by Google as the cost to ensure consistency is high and may result in broken data being read by the client.
Therefore GFS support Atomic Record Append in which many clients on different machines append to the same file concurrently.
-
Similar to record mutation
-
Extra steps is required: GFS picks offset to append data and returns it to client
-
Primary checks if appending record will exceed chunk max size If yes
- Pad chunk to maximum size
- Tell client to try on a new chunk
What if record append fail?
A: GFS does not guarantee that all replicas are bytewise identical. It only guarantees that the data is written at least once as an atomic unit
GFS Read
The reading process is much simpler than the writing process:
- Client will look for local cache of the file metadata, if not exisit -> Master File Name and chunk locations
- Master returns the chunk mata data to clients and client cache it
- Client calculates which chunks is required to read the data (local calculation)
- Client -> ChunkServer read request to that chunk. If the chunkserver doesnt have the data -> cache has expired. Client -> master for latest data
- Checksum calculation on chunk - If not ok read from other replica
GFS High Availability
High availability has two idea in this way, master node high availability and file data high availability.
Master High Availability
- We have mentioned that the Single Master Design. However there is a shadow master that exists as a slave of the master node
- Whenever there is a change to the metadata, the master will record the (WAL write ahead log) and save it to local disk
- This WAL will synced to the shadow master before a meta data changing process is considered successful
- After the shadow master has responded the successful WAL persistency, the master will then change the metadata in the RAM
- If the master is down, the Shadow master be be switched to Shadow Master Node in seconds (Chubby)
A bit similar to MySQL master <-> slave
- To ease the load of the master node, Lease is used to empower direct control of the data to the chunk server but not through master.
File Data High Availability
- Files are stored in chunks -> Three replica -> Ensure no file data will lost
- Master will maintain the chunk location information
- The amending process ensures the amending is successful only if it is successful on all the three replicas.
If a chunk server is down, the master will rebuild all chunks on that server using the data of the other two servers.
- GFS also maintains the chunksum of every chunk if held. If the data read from on chunkserver does not match the checksum, it will report to master and master will subsequently rebuild that chunk.
Chunk allocation
Distribution of the chunk of a file on different chunkserver is crucial too. There are 3 situation that GFS will initiate creation of a chunk.
- Initial new chunk creation
- Chunk Replication from other chunk server
- Rebalancing
No2 occurs when one chunkserver is down / checksum not correct. Master -> replicate a chunk from other chunkserver -> a new chunkserver
No3 occurs because the master will monitor the usage of the hardware of the chunkserver and will move some chunks away if the chunkserver is overloaded
The master will choose where to create the chunk based on the following algorithm:
- We want to place new replicas on chunkservers with below-average diskspace utilization.
- We want to limit the number of “recent” creations on each chunkserver. Preventing hot spot issue
- As discussed above, we want to spread replicas of a chunk across racks.
GFS Consistency Model
The record mutation and record append operation is different in terms of Record Atomicity
Example A

- There is a record mutation operation that to be carried out by the client on file A crossing the Chunk A and Chunk B
- However, when carrying out the mutation, chunk A succeeded whereas Chunk B fails.
- This will result in broken data as the mutation operation is not atomic.
Example B
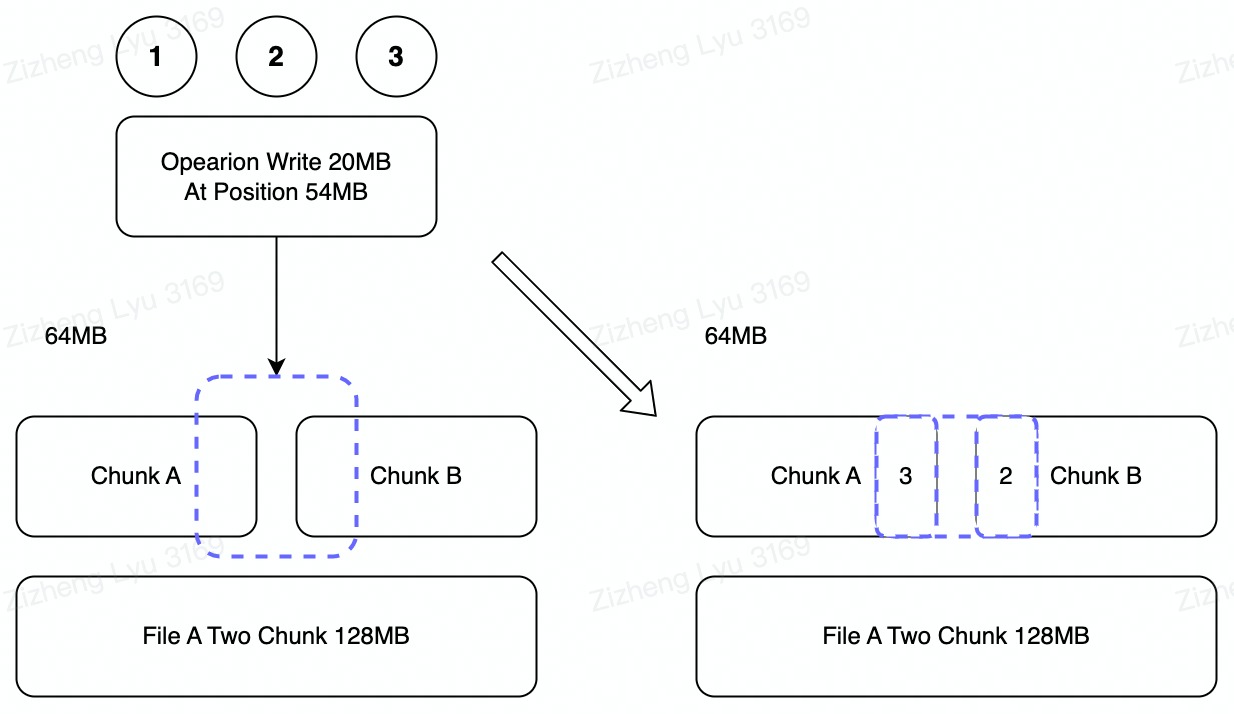
- There are 3 record mutation requests arrive at the same time and wants to mutate file a
- Assume the Chunk A carries out the mutation is 1 -> 2 -> 3 order however the Chunk B carries out the mutation order in 1 -> 3 -> 2.
- This will end up in broken data as the record mutation is not atomic
Record Append “Atomicity”
Contrast to record mutation, Atomic Record Append ensure no previous error will occur.
- Every writing is limited to 16MB
- If appending exceeds a chunk -> pad that chunk with nothing -> carry out at another chunk This ensures the record appending will always take effect on a single chunk rather than two chunks! Ans therefore ensures atomicity in record appending operation (no half done record muation and no mixed data in parallel mutation)
Multi Replica Consistency
How to ensure replica consistency if we keep multiple copies of a file.
However, we have mentioned that on a Single Operation that carries out Record Appending, we can ensure all replicas are consistent. (Recall writing process) Also, the atomic writing process also suggested the parallel operation of Atomic Record Appending will not cause broken data in all different chunks. However, it does not guarantee replica consistency!
GFS does not guarantee Cross Replica Atomicity. The copying to different replicas is not an atomic action.
- A record mutation is successful –> All replica successful
- A record mutation fail –> Some replica may be successful, some may fail GFS does not guarantee cross chunk atomicity also but it avoids that by using Atomic Record Appending.
- Record appending happens on single chunk…
GFS does not guarantee Cross Replica Atomicity. The copying to different replicas is not an atomic action.
- A record mutation is successful –> All replica successful
- A record mutation fail –> Some replica may be successful, some may fail GFS does not guarantee cross chunk atomicity also but it avoids that by using Atomic Record Appending.
- Record appending happens on single chunk…
Consistency Level By Google
- Inconsistent: Reading from any replica / any client / any where may read different result
- Consistent: Reading from any replica / any client / any where will read same data Our system IM is not strong consistent, we use MQ to achieve eventual consistency
- Defined: Firstly, it is consistent and secondly after a mutation action, the reading action will always read the latest data
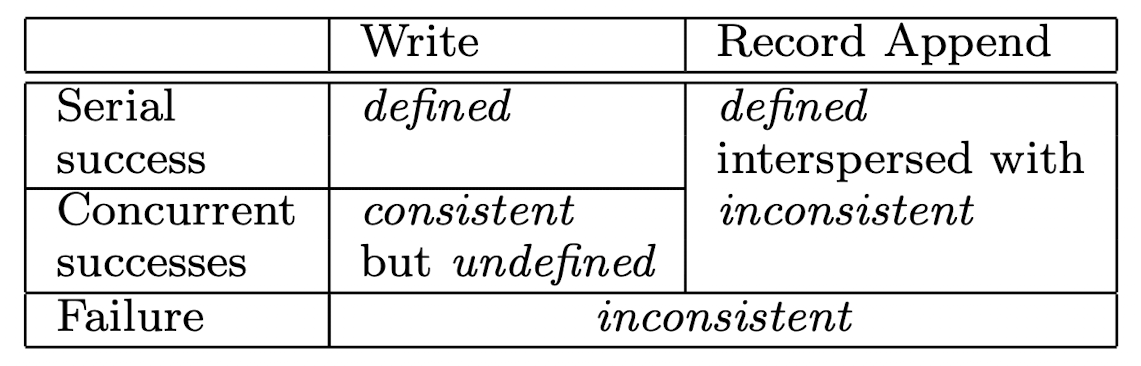
Record Mutation (Simple Writing Process)
- Serial Success : In a serial writing and successful cases, the mutation is not affected by any other action and GFS ensures all replica to be successful before the mutation is done –> Defined (Latest and consistent)
- Concurrent Success: Same as Example B -> Although the mutation success -> Chunk A will be same cross replica (Mutation3)-> Chunk B will be same cross replica (Mutation 2). Therefore the data will be consistent but not defined as it does not reflect with any kind of correct data.
- Failure: This is the case the writing and syncing to different replicas failed, GFS will return fail to user, thus the replica may have different records.
Atomic Record Append
When carrying out record append -> Fails on some replica -> Retry will not occur at same offset -> Continue to Append on that replica.
e.g. File A: AABBCC –> Write DDEEFF to File A
Replica 1: AABBCC –> DDEEFF ==> AABBCCDDEEFF
Replica 2: AABBCC –> DDE –X-> Retry
Retry:
Replica 1: AABBCCDDEEFF –> DDEEFF ==> AABBCCDDEEFFDDEEFF
Replica 2: AABBCC –> DDEEFF ==> AABBCCDDEEFF
Replica 3: AABBCC –> DDEEFF ==> AABBCCDDEEFF
You will read the latest data but not guarantee consistent
Insight
Therefore, GFS does not guarantee strong consistency even eventual consistency. It delivers loosely defined/consistent data , but may interpersed with some inconsisitent data.
GFS paper gives several suggestions for using GFS: relying on appends rather than overwrites, checkpointing, and writing self-validating, self-identifying records
Single Write –> Use Writing (Overwrite) from Begining to End
Method one:
- Wirte a temporary file for the first time
- After all the data is written successfully, rename the file to a permanent name and the reading of the file can only access it with the new permanent name
Method2:
- The writer writes the data in a certain sections. After the a single section is successful, record a checkpoint. (Application level checksum)
- The reader only reads the data before the checkpoint. Anything down -> continue from application level checkpoint to write -> fix inconsisitency.
Parallel Appending to a File End
Its more like a message queue producing to a single partition of a topic by different producers
- Use the record append API to ensure that data is successfully written at least once. However, the application needs to deal with inconsistent data and duplicate data.
- To verify inconsistent data, add a checkum to each record. The reader identifies wrong data by the checksum, and discards inconsistent data.
- If the reading is not idempotent, then the application needs to filter out duplicate data –> an additional unique identifier is required
Why does GFS use such ugly consistency model but not complicated algorithms to achieve that? GFS pursues a simple, enough to use idea that solves the problem of using cheap and vast amount of hardisks to store massive data, and achieve high I/O throughput and the file system has to be simple and easy to implement –> Developer went to develop Bigtable afterwards…. GFS achieved this but with some consistency problems, but in the beginning it’s a not a serious issue and GFS users (Bigtable), the application layer of the GFS deeply knows how to use it and therefore this inconsistency is avoided in the BigTable. https://queue.acm.org/detail.cfm?id=1594206
Master Level Consistency
- File namespace mutations (e.g. , file creation) are atomic as the master will lock the namespace when doing mutation
GFS MasterOperation (WIP)
Snapshot
The snapshot operation makes a copy of a file or a directory tree (the “source”) –minimize –> any interruptions of ongoing mutations.
Copy-on-write technique is used
- Master recycle all lease given to chunkserver
- Copy the meta data in master and name it as a copy: (RAM)
- e.g. Create a fila_backup (still pointing to the old chunks)
- Increase the reference number count of that chunk by one
- Chunk 4a3b used be used by filea only, now by filea_backup
- Master resumes lease and starts normal opeartion
- Next time is a chunk is mutated, we check its referral count > 1?
- If bigger than 1, create a new chunk duplicated from old chunk4a3b to chunk4a3b` and start writing on chunk4a3b
- The filea will point to chunk4a3b`
Namespace Management and Locking
Each master operation acquires a set of locks before it runs. Typically, if it involves /d1/d2/…/dn/leaf, it will acquire read-locks on the directory names:
- /d1,
- /d1/d2, …,
- /d1/d2/…/dn,
- Pluse a read or wirte lock on the /d1/d2/…/dn/node (that nodemay be a file or directory depending on the operation.)