I used to encounter an interesting issue, the Redis call has an increase in latency after I upgrade the network library dependency of my service RPC framework. The reason was that the pollers of RPC networker library occupy too much CPU and it grabs the default Redis netpoller’s CPU schedule. However, I could barely understand what happened in the networking part of the framework. So this session I will do a rough introduction on network packages
Beginning
For backend engineers its common we write an RPC server and provide varioud API for other client to make call through network. Usually an RPC server will open an TCP/UDP socket and accepts connections from the client. However there are a lot of frameworks that help us handle the network issue and we only need to write a KiteX/gRPC handler. We usually just implement the method of the generated code. Today, I will use Kite, right now KiteX as an example since its widely used in our comapny to demonstrate the journet of an RPC call from the socket level to the code level.
FYI, KiteX is a high perfromance go RPC framework developed by TikTok.
//kite: file: handler.go
//Implement LoadMorePerUserInbox Method.
func LoadMorePerUserInbox(ctx context.Context, r *message_api.PerUserMessagesRequest) (response *message_api.PerUserMessagesResponse, err error) {
//Implement your method here
return nil, nil
}
//or gRPC:
func (s *routeGuideServer) ListFeatures(rect *pb.Rectangle, stream pb.RouteGuide_ListFeaturesServer) error {
...
}
...
Also we know:
- OK, this call is handled by Kite framework.
- Its an RPC call, and we use thrift IDL to define the call content fields.
- The framework generates the serialisation code for us.
- The framework would accept TCP connection from clients and somehow transforms the tcp packet of the request and provides you with the content u need
- The framework somehow is so powerful and it handles hundreds of concurrent requests and manages hundreds of connections with clients
So the equesiton is, how does everything work with one another? What designs, patterns and features do they have to make a server robust and good? How does framework help u do a lot of things?
TCP Server (Linux)
UNIX Domain Socket
Sockets are the constructs that allow processes on different machines to communicate through an underlying network, being also possibly used as a way of communicating with other processes in the same host (through Unix sockets).
To create a TCP server, u need to create a UNIX socket by calling the socket(2)interface of the Linux System.

int main(int argc , char *argv[])
{
//Create struct for server addr and client addr
struct sockaddr_in cliaddr, servaddr;
//Create socket FD for TCP
listenfd = socket(AF_INET , SOCK_STREAM , 0);
//Prepare the sockaddr_in structure
server.sin_family = AF_INET;
server.sin_addr.s_addr = INADDR_ANY;
server.sin_port = htons( 8888 );
//Bind
bind(listenfd, (struct sockaddr *)&servaddr , sizeof(server));
//Listen
listen(socket_desc , 3);
//Accept
for ( ; ; ){
c = sizeof(struct sockaddr_in);
//Get a new socketfd from the listener queue
connfd = accept(socket_desc, (struct sockaddr *)&client, (socklen_t*)&c);
//Handle with connfd
//e.g. n = recv(connfd, buf, MAXLINE,0)
}
//Other Logics
return 0;
}
Insights:
- Linux System uses FD to manage sockets and connections. We create a global socket
listenfdas a listener on the socket address and for every connection we receive we create a new socket fdconnfdto handle it - To create a server, u need 4 init step:
create -> bind -> for loop listen -> accept a con -> read... Accept()function delivers you a socket from a queue of already accepted connections (TCP handshake finished). While the queue is empty, it blocks.
Issues:
- And how to handle a single connection? (How to read and write data from the
connfd) Connfdis a new file descriptor returned by the accept function. How to manage several connections?- How to manage
fdlife cycle? When do we delete it?
Network IO Model
Network IO has two kinds, synchronous and asynchronous. The difference is that whether the use process has to wait for the data copying form the kernel space to user space buffer.
Blocking IO Socket (Sync)
for ( ; ; ){
c = sizeof(struct sockaddr_in);
//Get a new socketfd from the
connfd = accept(socket_desc, (struct sockaddr *)&client, (socklen_t*)&c);
//Block here and await receive returns the data buffer
int recvlen = recv(connfd, buf, RECV_BUF_SIZE,0)
}

If ur user buffer is too small for the socket buffer received size, u need to call recv several times to receive all data. This is inconvenient.
Is the socket buffer the TCP sliding window? I actually dont now
“Non” Blocking IO Socket (Sync)
Its not true non blocking for data read. Its non blocking for data ready checking
// Change Socket to Non Blocking
int main(int argc , char *argv[])
{
//...
//Create socket FD
listenfd = socket(AF_INET , SOCK_STREAM , 0);
//Change to Non Blocking Sample
fcntl(sock_fd, F_SETFL, fdflags | O_NONBLOCK);
//Loop call
while(1) {
int recvlen = recv(sock_fd, recvbuf, RECV_BUF_SIZE) ;
......
}
//When system returns error like connection failed/terminated
close(connfd);
close(listenfd)
//Other Logics
return 0;
}

Insights:
- Handle a single connection by blocking IO or non blocking IO
- We use polling for non-blocking IO
Issues:
- Still dont know how to manage multiple connections
connfdon singlelistenfd - Polling looks so stupid
“Non” Blocking IO API (select, poll, epoll in Linux) (Sync)
We now see how Linux helps us manage multiple connections (whether there is data in connfd). Other systems like MacOS (UNIX based will use kqueue) will be omitted here
In Chinese context, this is commonly called IO Multiplexing (IO多路复用) and it is most commonly used is a lot of network libraries
Select
//return num of ready fds
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
- We omit the source code sample here as its getting complicated
- The
selecthasfd_setwhich is a fixed size buffer (max 1024 why?) to store all accepted connfd we accepted. Once any of the fd is ready forrecv(), it will inform our user about it. So that we wont block at therecv()function - The thing is that when the
fdis ready, it will amend the fd status in thefd_setto tell user that connfd is ready. However, it wont tell us which one, so we need to do the for loop on the fd_set to check intFD_ISSET(int fd, fd_set *fdset); - After checking, we need to put these fds back to the new fd_set to ask system to mange it. So it take O(n) * 2 time for checking and 2 times of data copying.
Poll
int poll (struct pollfd *fds, unsigned long nfds, int timeout);- Poll function improves the size limit of the array by using the pollfd field to mark the connfd array length. The first para is the first connfd pointer
- However, when the function returns, (the number of ready connfd), poll still dont tell us which one is ready.
Select and Poll Issues:
selectandpollbecomes heavy when there are a lot of client connfd as every time we call is (we do for loop on these functionsO(n)*2) we copy the all the connfds out from the kernel space to userspace and we still need to check on all the connfds we have and see which one is ready. If we have 10000 connfds. Data copy will occupy huge CPU.- Also, the kernel is doing another O(n) checking on all the connfd to check whether the fd is ready for event
Epoll
typedef union epoll_data {
int fd;
//...
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
//Core functions
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); // ready events will be stored in the array we passed in
-
epoll_create: Create an epoll instance (epollfd) and all rest operations are based on that instance -
epoll_ctl: We ask the epoll instance to take care of theconnfdorlistenfdwe have,by using operation like op(ADD/DEL/...), and we declare what kind of events we wanna pay attention to (EPOLLIN/EPOLLOUT/...)。 -
epoll_wait: Block until there is event ready for any fd in the epollfd, the reutrn value are the number of ready events and the ready ones will be stored in the array we passed in -
ET or LT
- To use
epoll_wait, we must know it has two modes: Edge trigger and Level Trigger. - ET will trigger epoll events only once when there is event occurring (e.g. readable)
- LT will trigger every time if the event can be carried out (e.g. Reading of the connfd buffer is not finished) If the package is huge, and the copying of data has not finished before the next call of epoll_wait occurs, it will trigger again and return the connfd ready event back
- To use
Level Triggered:
......
| |
________| |_________
Edge Triggered:
.____
| |
________.| |_________
- Epoll Events
EPOLLIN: readableEPOLLOUT: writableEPOLLIN+EPOLLRDHUP:- FIN Packet from other side (close or shutdown)
EPOLLIN+EPOLLHUP+EPOLLRDHUPEPOLLIN+EPOLLRDHUP+EPOLLHUP+EPOLLERR- When checking, we check a combination of events
Epoll Insights:
- Epoll prevents the user sapce <-> kennel space copyig of the
connfdfor every epoll_waitwe call and thus saves CPU (epoll uses a red-black tree to store all theconnfdand takes O(logn) to insert and delete) - Epoll prevents
O(n)checking of readyconnfdby returning the ready event directly to u. This is done through a system callback registered by the epoll to the system on everyconnfdit has epoll
Asynchronous IO
- Omitted here can do self research if interested
Handler Model
To summarise what we have learnt:
- We create a listener fd and listen networking events
- We create a connfd accept new connection established events on listener fd
- We use higher level system API to help us manage two things:
- Whether the is new connection of socket listenfd
- Whether every connfd is readable / closed ….
Reactor

Proactor
Omitted as its about Aynchronous Network IO pattern and we dont use it
NetWrok Library
The core funciton of a net library is to monitor/listen the status of a huge amount of connfds(via syscall) and respond to the status change/ event triggered efficiently and securely.

golang/net
Packages using net as default net library (redis, sarama, kite, grpc….)
TCP Server
Talk is cheap, show me the code
package main
import (
"log"
"net"
)
func main() {
//create listener
listen, err := net.Listen("tcp", ":8888")
if err != nil {
log.Println("listen error: ", err)
return
}
for { //block here to create connection
conn, err := listen.Accept()
if err != nil {
log.Println("accept error: ", err)
break
}
// start a new goroutine to handle the new connection.
go HandleConn(conn)
}
}
func HandleConn(conn net.Conn) {
defer conn.Close()
packet := make([]byte, 1024)
for { // block here if socket is not available for reading data.
n, err := conn.Read(packet)
if err != nil {
log.Println("read socket error: ", err)
return
}
// same as above, block here if socket is not available for writing.
_, _ = conn.Write(packet[:n])
}
}
Do you still recall the original socket programming when we create a listenerfd and accept an connfd
Does it looks a bit similar as the basic socket programming (listen -> bind -> accept -> read -> write -> close). However this net package look like a blocking pattern but its internals arr of great difference.
- Its a fake blocking pattern when writing go code but a very smart non-blocking io multiplexing using different kenel commands from internal. This helps eases developers’ effort in writing code. Developers do not have to care about context switch, goroutine scheduling and kernel network handling. Go netpoller is based on epoll/kqueue/iocp depending on which operating system it uses.
Insights
- Its uses
epollet mode in the bottom layer to handlerlistenerfdandconnfd - Every
listernerfdandconnfdcorresponds to a goroutine and uses a goroutine to handle each connection. However,listernerfdonly has one and its using main goroutine to do accept() net.Listen("tcp", ":8888")returns a*TCPListener, its a struct that implements thenet.Listenerinterface. listener.Accept() would create a new struct instance*TCPConnthat implements net.Conn interface and it containsnet.connstruct.- So we know
*TCPListener *TCPConnare supposed to contain these twolistenerfdandconnfd. So after read the source code, the fd are actually wrapped by a struct callednetFDnetFD contains apoll.FDstruct,andpoll.FDcaontains two thingsSysfdandpollDesc. - Sysfd are the actual
listenerfdandconnfdand pollDesc is an operator that controls the read write timeout and all other scheduling things.

Question: Is blocking wasting CPU resources?
Core Structs
// TCPListener is a TCP network listener. Clients should typically
// use variables of type Listener instead of assuming TCP.
type TCPListener struct {
fd *netFD
lc ListenConfig
}
// TCPConn is an implementation of the Conn interface for TCP network
// connections.
type TCPConn struct {
conn
}
// Conn
type conn struct {
fd *netFD
}
How dose netFD works
// Network file descriptor.
type netFD struct {
pfd poll.FD
// immutable until Close
family int
sotype int
isConnected bool // handshake completed or use of association with peer
net string
laddr Addr
raddr Addr
}
// FD is a file descriptor. The net and os packages use this type as a
// field of a larger type representing a network connection or OS file.
type FD struct {
// Lock sysfd and serialize access to Read and Write methods.
fdmu fdMutex
// System file descriptor. Immutable until Close.
Sysfd int
// I/O poller.
pd pollDesc
// Writev cache.
//...... other fields
}
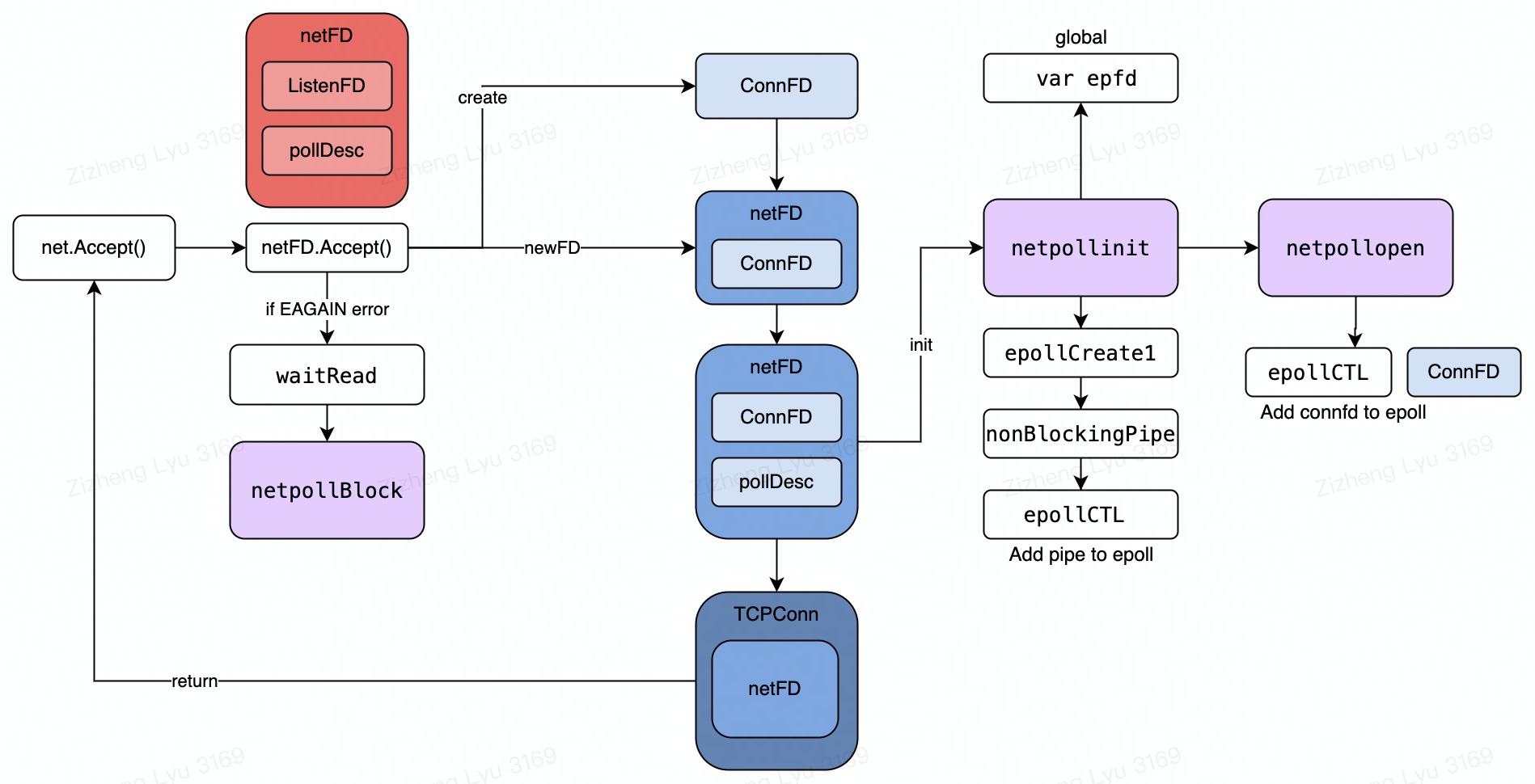
net.Listen

- After call
net.Listen, the bottom layer will create anlistenfdand use it to initialize the listener’snetFD, and then call thenetFD’slistenStreammethod to complete the bind &listen operation on the socket and then call init ofnetFD(mainly for the pollDesc initialization), the call chain isruntime.runtime _pollServerInit -- > runtime.poll _runtime_pollServerInit -- > runtime.netpollInit, the main things are:- Call
epollcreate1to create an epoll instanceepfd, which is used as the only event-loop for the entire runtime; - Call
netpollopento register the listenfd to the netpoll
- Call
net.Accept

netFDwill create aconnFDwhen itslistenFDis ready to accept new connectionnetFDwill go through the same init process on new connFD and add to epoll for listening- When there is no new connection which will get
EAGINerr,nefFDwill callpollDESC.waitReadto park the current goroutine, until the epoll informs that thelistenFDis ready, the waitRead will return and accept new connection
conn.Read

- netpollBlock would park the current goroutine and the detail is not elaborated (too complicated)
netPoll

-
Since Accept()/Read() goroutine wouble be parked by the netpollblock and therefore we need to a function that detect which one is ready
-
netpoll()would callepollwait()to constantly get ready to run connfd and listenfd so that the netpoll would know which corresponding fd is ready -
Netpollwould retriece thepollDescfrom the epollevent which saves the corresponding goroutine information -
Netpollwould then put that goroutine in to the readlist for runing -
Netpollis not constanly running, its called by the schedule at various places such as runtime.schedule() -
sysmonwill ensurenetpollget called very often
Issues:
- Reactor Model: One Reactor Multi Hander (goroutine) model and when connection is great on one machine, it will affect the performance of the programme
- Doesnt Support ZeroCopy, conn.Read(b []byte) will carry out a memory copy from kernel to user sapce then when we do unmarshalling of the byte, usually we will copy the data again since the memory allocated for the struct is not same as the one read from the network library
-
net.Connwont be closed by the server unless we read it and detect the error, since we are using epoll and when the other end closes the connection, the server side connection will still be there
cloudwego/netpoll
This package is the default network package of the TikTok’ Go RPC framework Kitex, which is a high performance (better than GRPC) framework for TikTok backends. So why it is better than the default network library.
Epoll ET vs LT
Still Recall Edge Trigger and Level Trigger?
Level Triggered:
......
| |
________| |_______
Edge Triggered:
.____
| |
________.| |_______
We cannot use this programming model for LT since there will be infinite triggering. We need to manage the buffer manually in the LT and cannot just let the goroutine to handle the []byte buffer on its own.
- Netpoll uses LT mode
- Netpoll uses LT because:
- the kernel team supports a thing call multisyscall
- Implements zerocopy buffer therefore cannot let every goroutine to handle the buffer individually
TCP Server
package main
import (
"context"
"time"
"code.byted.org/middleware/netpoll"
)
func main() {
//set poller number
netpoll.SetNumLoops(5)
// Create listener(wrapper on net.Listener)
listener, err := netpoll.CreateListener("tcp", "127.0.0.1:8888")
if err != nil {
panic("create netpoll listener fail")
}
// handler assign handler
var onRequest netpoll.OnRequest = handler
// options: EventLoop init options
var opts = []netpoll.Option{
netpoll.WithReadTimeout(1 * time.Second),
netpoll.WithIdleTimeout(10 * time.Minute),
netpoll.WithOnPrepare(nil),
}
// Create EventLoop
eventLoop, err := netpoll.NewEventLoop(onRequest, opts...)
if err != nil {
panic("create netpoll event-loop fail")
}
// Run Server and pass in the listener
err = eventLoop.Serve(listener)
if err != nil {
panic("netpoll server exit")
}
}
// Handler on connection
func handler(ctx context.Context, connection netpoll.Connection) error {
return connection.Writer().Flush()
}
Insights:
- Unlike the net package we have the system netpoll to be the poller, we need custom poller for connection management NewEventLoop
- Listener looks same
- We dont create goroutine for every connection but let the package to help manage the user side handling (go routine creatioin / arrangement) since we are using LT mode of the epoll.
- We are still unclear about how to manage buffer, how to manage connection and how to manage handler goroutine
CoreStruct:

Conn/Listener (FDOperator)
- Similar to
NetFDin default net package, bothlistenfdandconnfdare these wrappers contains an FDOperator
// FDOperator is a collection of operations on file descriptors.
type FDOperator struct {
// FD is file descriptor, poll will bind when register.
FD int
// The FDOperator provides three operations of reading, writing, and hanging.
// The poll actively fire the FDOperator when fd changes, no check the return value of FDOperator.
OnRead func(p Poll) error //for listener
OnWrite func(p Poll) error //for listener
OnHup func(p Poll) error //for listener
// The following is the required fn, which must exist when used, or directly panic.
// Fns are only called by the poll when handles connection events.
Inputs func(vs [][]byte) (rs [][]byte) //for connection
InputAck func(n int) (err error) //for connection
// Outputs will locked if len(rs) > 0, which need unlocked by OutputAck.
Outputs func(vs [][]byte) (rs [][]byte, supportZeroCopy bool) //for connection
OutputAck func(n int) (err error) //for connection
// poll is the registered location of the file descriptor.
poll Poll
// private, used by operatorCache
next *FDOperator
state int32 // CAS: 0(unused) 1(inuse) 2(do-done)
}
Poller
// Poll monitors fd(file descriptor), calls the FDOperator to perform specific actions,
// and shields underlying differences. On linux systems, poll uses epoll by default,
// and kevent by default on bsd systems.
type Poll interface {
// Wait will poll all registered fds, and schedule processing based on the triggered event.
// The call will block, so the usage can be like:
//
// go wait()
//
Wait() error
// Close the poll and shutdown Wait().
Close() error
// Trigger can be used to actively refresh the loop where Wait is located when no event is triggered.
// On linux systems, eventfd is used by default, and kevent by default on bsd systems.
Trigger() error
// Control the event of file descriptor and the operations is defined by PollEvent.
Control(operator *FDOperator, event PollEvent) error
}
//github.com/cloudwego/[email protected]/poll_default_linux.go
type defaultPoll struct {
pollArgs
fd int // epoll fd
wop *FDOperator // eventfd, wake epoll_wait
buf []byte // read wfd trigger msg
trigger uint32 // trigger flag
// fns for handle events
Reset func(size, caps int)
Handler func(events []epollevent) (closed bool)
}
type pollArgs struct {
size int
caps int
events []epollevent
barriers []barrier
}
- Poller is a wrapper around the epoll instance, it waits/listens/acts on the events based on what is returned by the epoll
Init Poll Management:
func init() {
var loops = runtime.GOMAXPROCS(0)/20 + 1 //number of poller
pollmanager = &manager{}
pollmanager.SetLoadBalance(RoundRobin)
pollmanager.SetNumLoops(loops)
}
type manager struct {
NumLoops int
balance loadbalance // load balancing method (round robin)
polls []Poll // all the polls
}
func (m *manager) Run() error
func (m *manager) Pick() Poll
- During init the netpoll package would create a poll amanger that we can think as a poller array that will create their own
epollfd - PollManager will create the number of NumLoops Pollers to run
- The load balancer is default to be round robin that is to say when a new connection comes, the
pollmanagerwould pick a poller to handle that connection and its by round robin pollmanagerthen will let all poller to run and since there is no FDOperator being added (listnerfdandconnfd) it wont trigger and event callbackgo poll.Wait()every poller will use a goroutine to run
Why do we need multiple poller and net package only have one poller which is the for loop
Poller Wait
If we use the net package model, What is the P99 for every connection? If the read() would cost same time as handle(), how many CPU can this function utilise?

- Poller awaits for event and synchronously handles all event one by one in a blocking way
- This is heavy as we dont have new goroutine to handle every connfd (read write buffer)
- The team has optimise it in a crazy way!
- Dynamic
msec - Active
runtime.Gosched() RawSyscall6to prevent runtime schedule
- Dynamic
// Wait implements Poll.
func (p *defaultPoll) Wait() (err error) {
// msec is the time the EpollWait need to wait before returns anything
//0 means instant return
//-1 means blocking
//10 means return in 10ms (iirc)
var caps, msec, n = barriercap, -1, 0
p.Reset(128, caps)
// wait
for {
if n == p.size && p.size < 128*1024 {
p.Reset(p.size<<1, caps)
}
n, err = EpollWait(p.fd, p.events, msec)
if err != nil && err != syscall.EINTR {
return err
}
if n <= 0 {
//This mean the previous loop n must be > 0
//So this round no event (LT events finished)
//Set epollwait to be -1 blocking to reduce syscall
msec = -1
//Actively quit scheduling and delay next EpollWait
//since next call will most likely be await for new events and blocked
runtime.Gosched()
continue
}
//This means n > 0 and it means there are events happening
//Likely next for loop there will also be events (LT)
//Set epoll wait to zero in speed it up
msec = 0
if p.Handler(p.events[:n]) {
return nil
}
}
}
func EpollWait(epfd int, events []epollevent, msec int) (n int, err error) {
var r0 uintptr
var _p0 = unsafe.Pointer(&events[0])
if msec == 0 {
r0, _, err = syscall.RawSyscall6(syscall.SYS_EPOLL_WAIT, uintptr(epfd), uintptr(_p0), uintptr(len(events)), 0, 0, 0)
} else {
r0, _, err = syscall.Syscall6(syscall.SYS_EPOLL_WAIT, uintptr(epfd), uintptr(_p0), uintptr(len(events)), uintptr(msec), 0, 0)
}
if err == syscall.Errno(0) {
err = nil
}
return int(r0), err
}
Actively call gosched will release scheduler P before runtime syscall on epollwait. This will let the scheduler to run more urgent goroutine and delay the epollwait syscall on this poller. Theoritically in this way there is one more syscall compared to normal for loop. However, there is a delay and let other goroutine to probably finish their task and also increased the probablity of the syscall on epollwait will have ready events and return directly.
Run Server
New Server eventLoop.Serve(listener)
type server struct {
operator FDOperator
ln Listener
prepare OnPrepare // 连接创建后的准备工作(注册到 epoll 中去)
quit func(err error)
connections sync.Map // key=fd, value=connection
}
func (s *server) Run() (err error)
func (s *server) Close(ctx context.Context) error
func (s *server) OnRead(p Poll) error
func (s *server) OnHup(p Poll) error
- Run would create a FDOperator of the listenFD and register the FDOperator to one of the poller
- Register the listener OnRead/OnHup handler to the FDOperator
Poller Control For Server
Poller Control is to add the FDOperator’s connfd or listenfd to the epoll and register the epoll events using uintptr
// Control implements Poll.
func (p *defaultPoll) Control(operator *FDOperator, event PollEvent) error {
var op int
var evt epollevent
//store the FDOperator pointer to the epoll event
*(**FDOperator)(unsafe.Pointer(&evt.data)) = operator
//e.g. readable event
op, evt.events = syscall.EPOLL_CTL_ADD, syscall.EPOLLIN|syscall.EPOLLRDHUP|syscall.EPOLLERR
return EpollCtl(p.fd, op, operator.FD, &evt)
}
Poller Wait For Server
The actually handler for poller wait for server event
func (p *defaultPoll) handler(events []epollevent) (closed bool) {
for i := range events {
//Get operator
var operator = *(**FDOperator)(unsafe.Pointer(&events[i].data))
if !operator.do() {
continue
}
// trigger or exit gracefully
// skip
evt := events[i].events
// check poll in
if evt&syscall.EPOLLIN != 0 {
operator.OnRead(p)
}
// check hup
if evt&(syscall.EPOLLHUP|syscall.EPOLLRDHUP) != 0 {
p.appendHup(operator)
continue
}
operator.done()
}
// hup conns together to avoid blocking the poll.
p.detaches()
return false
}
New Connection listenerFDOperator.Onread()
- Server
OnRead()will be called to handler new connection.listener.Acceptwill be called to get the new connectionFD- Accept a new
netFDstruct - Init a new
connectionand set its fields - Allocate the fields
- Init the
FDOperator - Set the options created to the listener (still remember the timeouts?)
- Register the
FDOperatorto its poller
- Accept a new
type Connection interface {
//兼容 API,不推荐使用
net.Conn
//zero-copy reader & writer
Reader() Reader
Writer() Writer
IsActive() bool
SetReadTimeout(timeout time.Duration) error
SetIdleTimeout(timeout time.Duration) error
SetOnRequest(on OnRequest) error
//由于存在被动关闭的情况,所以需要注册关闭回调
AddCloseCallback(callback CloseCallback) error
}
type Reader interface {
Next(n int) (p []byte, err error)
Peek(n int) (buf []byte, err error)
Skip(n int) (err error)
ReadString(n int) (s string, err error)
ReadBinary(n int) (p []byte, err error)
ReadByte() (b byte, err error)
Slice(n int) (r Reader, err error)
Release() (err error)
Len() (length int)
}
type Writer interface {
Malloc(n int) (buf []byte, err error)
WriteString(s string) (n int, err error)
WriteBinary(b []byte) (n int, err error)
WriteByte(b byte) (err error)
WriteDirect(p []byte, remainCap int) error
MallocAck(n int) (err error)
Append(w Writer) (n int, err error)
Flush() (err error)
MallocLen() (length int)
}
// connection is the implement of Connection
type connection struct {
netFD
onEvent
locker
operator *FDOperator
readTimeout time.Duration
readTimer *time.Timer
readTrigger chan struct{}
waitReadSize int32
writeTrigger chan error
inputBuffer *LinkBuffer
outputBuffer *LinkBuffer
inputBarrier *barrier
outputBarrier *barrier
supportZeroCopy bool
maxSize int // The maximum size of data between two Release().
bookSize int // The size of data that can be read at once.
}
Poller Control For Connection
Same as server
Buffer Management Linked Buffer
We knew that to copy the data out from the kernel sapce we need to create a buffer for every connection. However, to maximise throughput we need to support stream reading and steam writing to let STEP1 And STEP2 to go concurrently.
- Ring buffer is a good choice
- Supports read and write at same time
- Need to expand when the data is full
- So an expansion is requried and copy of data is inevitable
- Data Race problem
- Lock and performance drop


- Use a bufferpool github.com/bytedance/gopkg to manage memory buffers
- For every connection we have two linked buffer for (STEP1 and STEP2)read buffer and (STEP3 and STEP4) write buffer

Why this is not used by other company? ReadV is not implemented by golang runtime but BytaDance team….. How do we know how many bytes we need to read before STEP2 occur? Do we jsut read as many bytes available in the buffer?
Poller Wait For Connection
- The poller will call
Inputsto acquire a[][]bytearray with 8kb - Call
readvto do a rawsyscall to read the data into a 2-dimentional array (linked bytebuffer) - Ack the reading as finished by calling
InputAck,- It will trigger the
Onrequestfunction J,it has a lock - which will trigger
TriggerRead()and this will awake the goroutine that is running the task
- It will trigger the
//synchrounou handler by poller
func (p *defaultPoll) handler(events []epollevent) (closed bool) {
for i := range events { // loop epoll events returned
var operator = *(**FDOperator)(unsafe.Pointer(&events[i].data))
evt := events[i].events
switch {
// ...
case evt&syscall.EPOLLIN != 0: // epoll read
// acquire a linked buffer from linked buffer and book for 8kb
var bs = operator.Inputs(p.barriers[i].bs)
if len(bs) > 0 {
var n, err = readv(operator.FD, bs, p.barriers[i].ivs) // syscall
operator.InputAck(n)
if err != nil && err != syscall.EAGAIN && err != syscall.EINTR { // read fail and hop
hups = append(hups, operator)
break
}
}
case evt&syscall.EPOLLOUT != 0: // epoll write
//..skip outputs and outputsack
}
}
}
// inputAck implements FDOperator.
func (c *connection) inputAck(n int) (err error) {
if n <= 0 {
c.inputBuffer.bookAck(0) //convert the buffer to be readable
return nil
}
var needTrigger = true
if length == n { // first start onRequest
needTrigger = c.onRequest() //if alr started then just trigger next reading
}
if needTrigger && length >= int(atomic.LoadInt32(&c.waitReadSize)) {
c.triggerRead()
}
return nil
}
- If there is no task running, the onRequest will create a goroutine from the goroutine pool to run the handler we created
- Then the
handlerwill start to read from the buffer depends on the protocol we use (thirift binary) ↓↓↓
// Handler on connection
func handler(ctx context.Context, connection netpoll.Connection) error {
//connection.Reader().Next()
//connection.Reader().Slice()
return connection.Writer().Flush()
}
// Next implements Connection.
func (c *connection) Next(n int) (p []byte, err error) {
if err = c.waitRead(n); err != nil {
return p, err
}
return c.inputBuffer.Next(n)
}
Architecture

Net VS NetPoll
golang/net
- Use Epoll ET
- Single Poller
- Goroutine perconnection
- User manage reading
- No max goroutine limitation
- No zero copy on buffered connecction
cloudwego/netpoll:
- Use Epoll LT
- Multi Poller
- Poller handle connection
- Poller handles reading
- Goroutine is recycled to routine pool
- BufferPool by linkedbuffer
Extra: RPC Framework
Transport/Protocol(Thrift)
Transport means the trasport rule we use to specify the data packet that are sent out by the Server
- Buffered Transport
- Framed Transport
- THeader transport
- TTHeaderFramed
Not elaborate here Jiale will do more on thrift next week. By default we use buffered transport for kite.

For porotocal we support BinaryProtocol and Compact protocol by default using Binary Protocol So we dont talk abotu mesh here we just talk about two default BufferedProtocol Transport
Kite
Kite use golang/net library as its network library and lets see how it converts the user buffer to RPC request struct.
Core Interfaces and Impl
Kite has three core struct here which are TTransport, TProtocol and TProcessor which corresponds to handling the
TTransport
type TTransport interface {
io.ReadWriteCloser
Flusher
// Opens the transport for communication
Open() error// Returns true if the transport is open
IsOpen() bool
}
//IMPL
type TBufferedTransport struct {
bufio.ReadWriter //Buffer pool to get golang bufio
tp TTransport
}
TTransport is a wrapper on the socket and has different implementation. It operates the socket buffer and handles the Transport Level staff. e.g. TBufferedTransportT
TProtocol
//gopkg/thrift/protocol.go
type TProtocol interface {
WriteMessageBegin(name string, typeId TMessageType, seqid int32) error// ......
ReadMessageBegin() (name string, typeId TMessageType, seqid int32, err error)
WriteStructBegin(name string) error
WriteStructEnd() error
// ......
Transport() TTransport
}
//IMPL
type TBinaryProtocol struct {
trans TRichTransport
origTransport TTransport
reader io.Reader
writer io.Writer
strictRead bool
strictWrite bool
buffer [64]byte
}
TPortocol is also an interface with some methos ReadMessageBegin、WriteMessageBegin、ReadI64、WriteI64.
TProtocol also contains Transport() to return the Transport Instance it is to read data from transport layer and do deserialisation/seraialisation.
TProcessor
// A processor is a generic object which operates upon an input stream and
// writes to some output stream.
type TProcessor interface {
Process(in, out TProtocol) (bool, TException)
}
//im.conversation.api2 -> finally have somethign famliar
type ConversationServiceProcessor struct {
processorMap map[string]thrift.TProcessorFunctionWithContext
handler ConversationService
}
RPC Handlin Process
InitServer
func main(){
kite.Init()
kite.Run()
}
func Init() {
//1.SetMacPROC
//2.InitConf
//3.InitMetrics/tracing
//...
// create the singleton server instance
RPCServer = NewRpcServer() // 3
_, processorSupportContext = Processor.(thrift.TProcessorWithContext)
}
type RpcServer struct {
l net.Listener
processorFactory thrift.TProcessorFactory
transportFactory thrift.TTransportFactory
protocolFactory thrift.TProtocolFactory
remoteConfiger *remoteConfiger
overloader *overloader
}
- Set max P for goroutine
- Init configs and other logging and tracing and metric
- Create a new RPC server that contains a
listnerFD, the three core interface factory. Other configs like max concurrent connections
// Run starts the default RpcServer.
// It blocks until recv SIGTERM, SIGHUP or SIGINT.
func Run() error {
errCh := make(chan error, 1)
go func() { errCh <- RPCServer.ListenAndServe() }() //never stop server
if err := waitSignal(errCh); err != nil {
return err
}
return RPCServer.Stop()
}
// ListenAndServe ...
func (p *RpcServer) ListenAndServe() error {
l, err := p.CreateListener()
//...
return p.Serve(l)
}
// CreateListener .
func (p *RpcServer) CreateListener() (net.Listener, error) {
var addr string
//ListenType TCP
l, err := net.Listen(ListenType, addr)
//..
return l, nil
}
// Serve ...
func (p *RpcServer) Serve(ln net.Listener) error {
if p.l != nil {
panic("KITE: Listener not nil")
}
p.l = ln
p.processorFactory = thrift.NewTProcessorFactory(Processor)
p.startDaemonRoutines()
//..
for {
stream, err := p.l.Accept()
//..skip
go p.handleConn(stream, isShmIPC)
}
}
//
func (p *RpcServer) handleConn(conn net.Conn, isShmIPC bool) {
// skip panic handler, overloader
//Call factory to create the processor transport and protocol instances
ctx, processor, transport, protocol := p.prepareRequests(conn, isShmIPC)
// close conn
var closer io.Closer = transport
defer closer.Close()
handleRPC := func() {
if err := p.processRequests(ctx, processor, transport, protocol); err != nil {
//log
}
}
if processorSupportContext {
handleRPC()
} else {
if enableGLS || GetRealIP {
// Use gls to pass context
glsStorage := gls.NewStorage()
//handler
} else {
handleRPC()
}
}
}
//processRequests
if processorSupportContext {
ok, err = processor.(thrift.TProcessorWithContext).ProcessWithContext(ctx, protocol, protocol)
} else {
ok, err = processor.Process(protocol, protocol)
}
Processor
func init() {
kite.Processor = message_api.NewImMessageServiceProcessor(&ImMessageServiceHandler{})
}
func NewImMessageServiceProcessor(handler ImMessageService) *ImMessageServiceProcessor {
//store ur handler name in a processor map
//We use string because the thrift would encode the handler name as a string
self123 := &ImMessageServiceProcessor{handler: handler, processorMap: make(map[string]thrift.TProcessorFunctionWithContext)}
self123.processorMap["SendMessage"] = &imMessageServiceProcessorSendMessage{handler: handler}
self123.processorMap["GetMessagePerUserInbox"] = &imMessageServiceProcessorGetMessagePerUserInbox{handler: handler}
self123.processorMap["LoadMorePerUserInbox"] = &imMessageServiceProcessorLoadMorePerUserInbox{handler: handler}
self123.processorMap["LoadMorePerConversationInbox"] = &imMessageServiceProcessorLoadMorePerConversationInbox{handler: handler}
//....
}
// TProtocol will find the handler name according to the Protocol u use (Binary)
func (p *ImMessageServiceProcessor) ProcessWithContext(ctx context.Context, iprot, oprot thrift.TProtocol) (success bool, err thrift.TException) {
// message begin -> method name such as "LoadMorePerUserInbox"
name, _, seqId, err := iprot.ReadMessageBegin()
if err != nil {
return false, err
}
if processor, ok := p.GetProcessorFunction(name); ok {
return processor.Process(ctx, seqId, iprot, oprot)
}
// If no handler is found
iprot.Skip(thrift.STRUCT)
iprot.ReadMessageEnd()
x62 := thrift.NewTApplicationException(thrift.UNKNOWN_METHOD, "Unknown function "+name) //famliar right
oprot.WriteMessageBegin(name, thrift.EXCEPTION, seqId)
x62.Write(oprot)
oprot.WriteMessageEnd()
oprot.Flush()
return false, x62
}
Then we start to read the request and write the response. The implementation of the process and read and write is generated by the code gen
//code.byted.org/im_cloud/common_tiktok/gen/thrift_gen/message_api/immessageservice.go
func (p *imMessageServiceProcessorSendMessage) Process(ctx context.Context, seqId int32, iprot, oprot thrift.TProtocol) (success bool, err thrift.TException) {
args := SendMessageArgs{} //new send msg request
if err = args.Read(iprot); err != nil { //read
//handle error
return false, err
}
iprot.ReadMessageEnd()
result := SendMessageResult{}
var retval *SendMessageResponse
var err2 error
if retval, err2 = p.handler.SendMessage(ctx, args.Req); err2 != nil {
//error
return true, err2
} else {
result.Success = retval
}
//oprot.WriteMessageBegin("SendMessage", thrift.REPLY, seqId)
if err2 = oprot.WriteMessageBegin("SendMessage", thrift.REPLY, seqId)
if err2 = result.Write(oprot); //..
if err2 = oprot.WriteMessageEnd();//..
if err2 = oprot.Flush();//..
return true, err
}
//Read Struct
func (p *SendMessageArgs) Read(iprot thrift.TProtocol) error {
if _, err := iprot.ReadStructBegin();
for {
_, fieldTypeId, fieldId, err := iprot.ReadFieldBegin()
if fieldTypeId == thrift.STOP { //finish reading
break
}
switch fieldId {
case 1:
if err := p.ReadField1(iprot);
default:
if err := iprot.Skip(fieldTypeId);
}
if err := iprot.ReadFieldEnd();
}
if err := iprot.ReadStructEnd();
return nil
}
Reference
https://www.cs.dartmouth.edu/~campbell/cs50/socketprogramming.html https://www.cs.dartmouth.edu/~campbell/cs50/socketprogramming.html https://www.venafi.com/blog/does-tcp-fast-open-improve-tls-handshakes https://codeantenna.com/a/SdTXxsiy6g https://blog.csdn.net/shaosunrise/article/details/106957899 https://www.masterraghu.com/subjects/np/introduction/unix_network_programming_v1.3/ch06lev1sec2.html https://strikefreedom.top/archives/go-netpoll-io-multiplexing-reactor#toc-head-13 https://tech.bytedance.net/articles/13427#heading1 https://tech.bytedance.net/articles/7086814560904019981 https://tech.bytedance.net/articles/6969850747026407432#heading38 https://tech.bytedance.net/articles/7086814560904019981#h6LcT6